diff --git a/.gitignore b/.gitignore
index 6503652..7ca9590 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,2 +1,3 @@
/.idea/
-/项目/
\ No newline at end of file
+/项目/
+/.playwright-mcp/
diff --git a/articles/007-国产模型杀疯了!通义千问Qwen3.5登顶中国第一,凭什么超越GPT-5.4.md b/articles/007-国产模型杀疯了!通义千问Qwen3.5登顶中国第一,凭什么超越GPT-5.4.md
new file mode 100644
index 0000000..ba64155
--- /dev/null
+++ b/articles/007-国产模型杀疯了!通义千问Qwen3.5登顶中国第一,凭什么超越GPT-5.4.md
@@ -0,0 +1,251 @@
+# 国产模型杀疯了!通义千问 Qwen3.5 登顶中国第一,凭什么超越 GPT-5.4?
+
+> 发布日期:2026-03-29
+> 分类:技术解读 / 深度分析
+> 作者:老邓唠AI
+
+
+
+## 引子:中国模型,第一次站到了这个位置
+
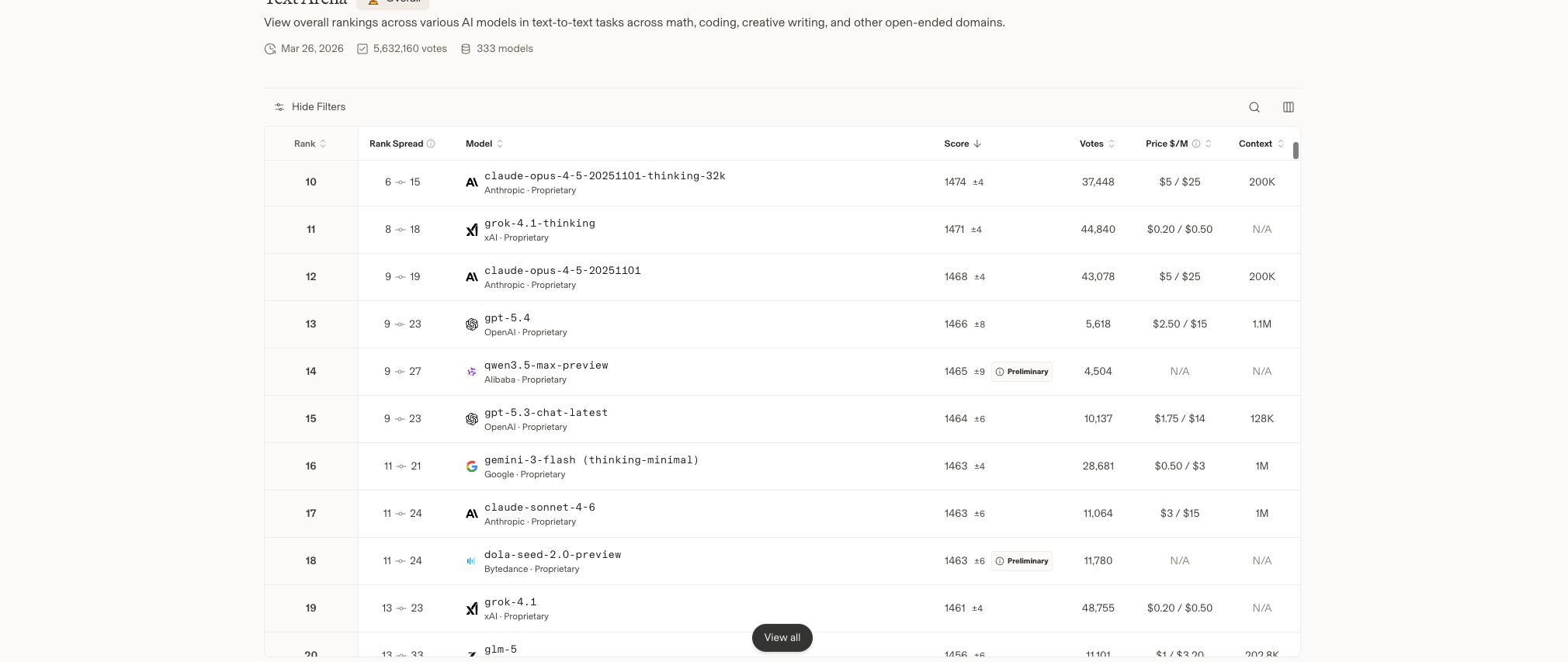
+3 月 20 日,阿里悄悄在全球最权威的大模型竞技平台 LMArena 上提交了一个新模型——**Qwen3.5-Max-Preview**。
+
+结果一出,整个 AI 圈炸了。
+
+**1464 分,全球公司排名第五,中国第一。**
+
+它超越了 OpenAI 的 GPT-5.4、xAI 的 Grok 4.1、字节的豆包 2.0、智谱的 GLM-5、月之暗面的 Kimi 2.5——几乎打遍了国内外一众顶尖选手。
+
+
+
+要知道,这还只是一个**预览版**。正式版还没发。
+
+今天就来拆解一下:通义千问 Qwen3.5 到底强在哪?这个"中国第一"的含金量有多高?普通人又能怎么用?
+
+---
+
+## 一、LMArena 是什么?为什么它的排名最有说服力?
+
+在聊 Qwen3.5 之前,先说说 LMArena 这个平台——因为不是所有排行榜都值得看。
+
+### 传统跑分的问题
+
+我们常见的 MMLU、HumanEval、GPQA 这些基准测试,本质上是**标准化考试**。模型厂商可以针对性训练、刷分、甚至"背题"。就像学生刷模拟卷能拿高分,但不代表真实水平。
+
+### LMArena 的不同之处
+
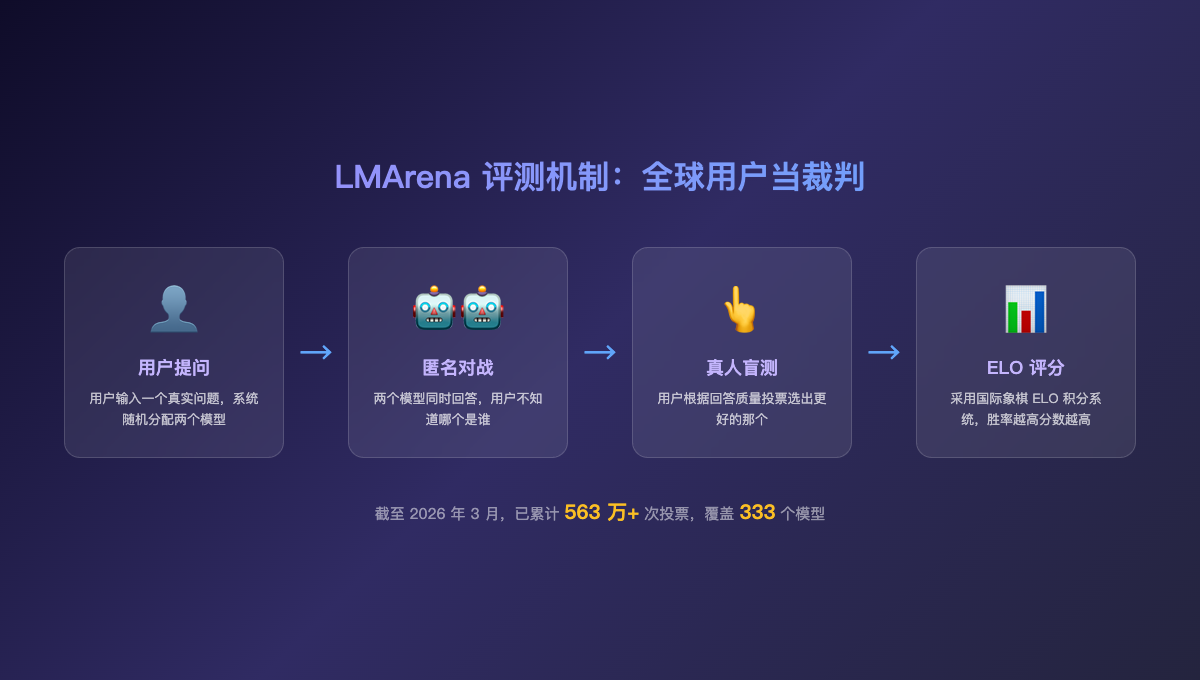
+LMArena(原 LMSYS Chatbot Arena)采用的是一套完全不同的评测机制:
+
+
+
+1. **匿名对战**:两个模型的回答并排展示,用户不知道哪个是谁
+2. **真人盲测**:全球开发者根据回答质量投票选出胜者
+3. **ELO 评分**:采用国际象棋的 ELO 积分系统,胜率越高分数越高
+4. **规模庞大**:截至 2026 年 3 月,已有超过 **563 万次投票**,覆盖 **333 个模型**
+
+简单说,LMArena 不是模型自己考试,而是**让全球用户当裁判,真刀真枪地 PK**。这就是为什么它被公认为最权威的大模型评测平台。
+
+---
+
+## 二、当前全球大模型排行格局
+
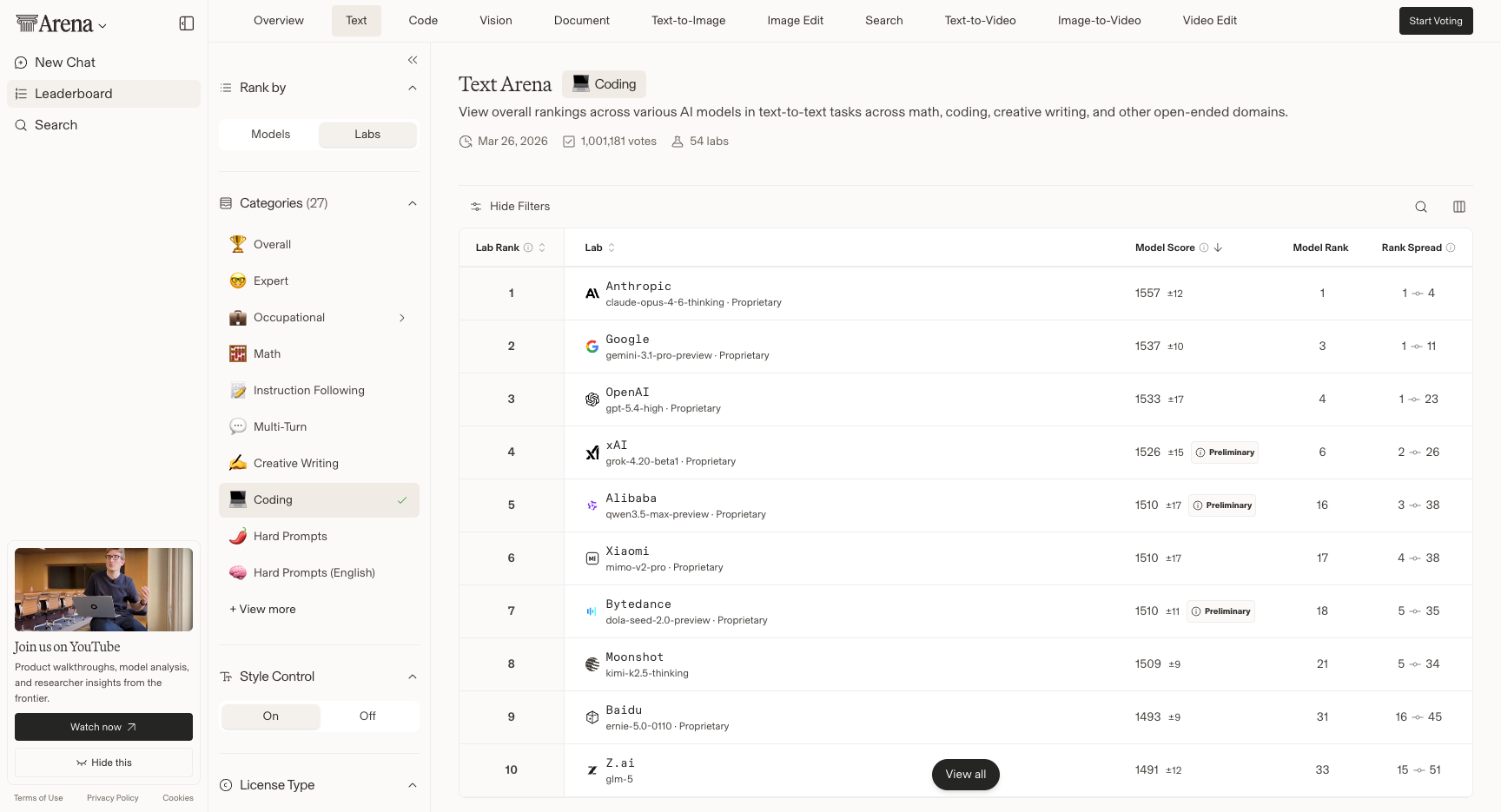
+先看大盘。截至 2026 年 3 月底,LMArena 文本排行榜的竞争格局如下:
+
+### LMArena 全球 Top 模型排名
+
+| 排名 | 模型 | 公司 | ELO 分数 | 亮点 |
+|------|------|------|---------|------|
+| 1 | Claude Opus 4.6 | Anthropic | 1504 | 综合最强,编程之王 |
+| 2 | Gemini 3.1 Pro Preview | Google | 1500 | 科学推理 GPQA 94.3% 史上最高 |
+| 3 | Claude Opus 4.6 Thinking | Anthropic | ~1500 | 推理增强版 |
+| 4 | Grok 4.20 Beta | xAI | 1493 | 马斯克旗下,进步飞快 |
+| 5 | Gemini 3 Pro | Google | 1485 | 多模态标杆 |
+| 6 | GPT-5.4 Thinking | OpenAI | — | Agent 能力超越人类基线 |
+| ... | ... | ... | ... | ... |
+| **中国第一** | **Qwen3.5-Max-Preview** | **阿里** | **1464** | **全球公司排名第五** |
+
+
+
+### 关键结论:没有绝对的"最强"
+
+现在的大模型竞争已经进入**多极化时代**,各家都有自己的长板:
+
+- **Claude Opus 4.6**:LMArena 综合第一,SWE-Bench 编程 80.9%,代码工程最强
+- **Gemini 3.1 Pro**:科学推理 GPQA 94.3%,学术研究首选
+- **GPT-5.4**:OSWorld 75% 桌面操作超越人类,Agent 能力最强
+- **Qwen3.5**:开源最强 + 性价比之王 + 原生多模态,中国第一
+
+而 Qwen3.5 的位置非常特殊——它是这个顶级梯队里**唯一的开源模型**,也是**唯一的中国模型**。
+
+---
+
+## 三、Qwen3.5 到底强在哪?
+
+现在来拆解 Qwen3.5 本身。它能拿到这个排名,不是靠运气,而是有实打实的技术创新。
+
+### 3.1 全球首个原生多模态 MoE 大模型
+
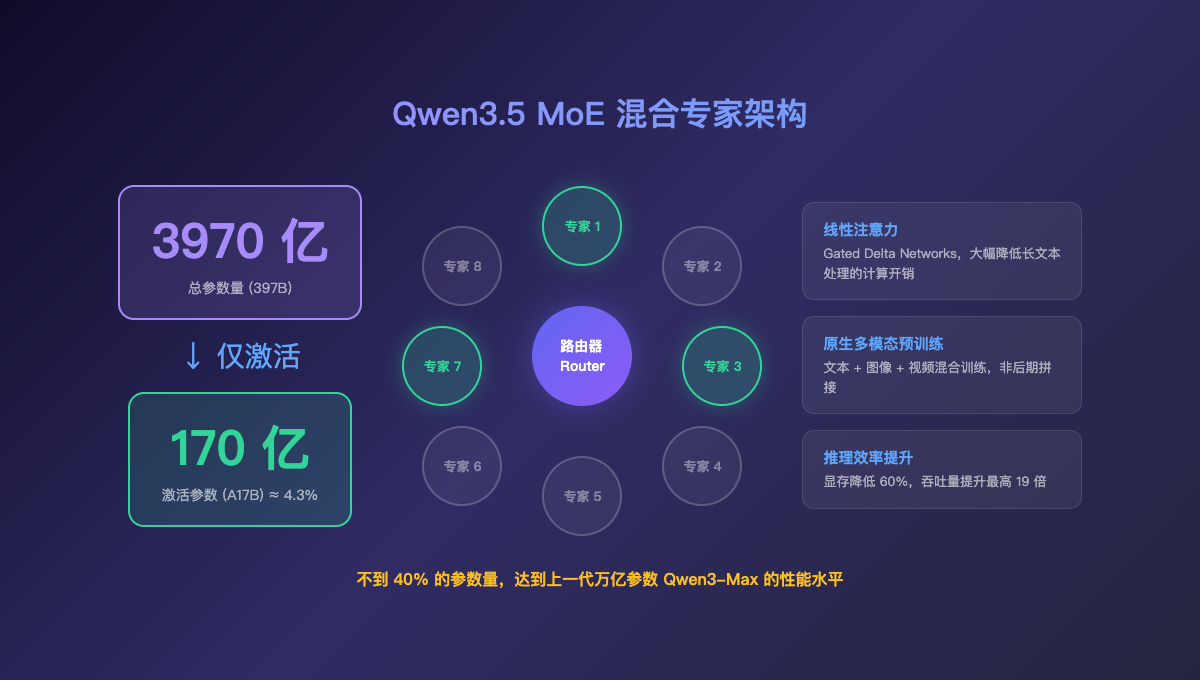
+Qwen3.5-397B-A17B 这个型号名已经说明了一切:
+
+- **397B**:总参数 **3970 亿**
+- **A17B**:每次推理仅激活 **170 亿** 参数
+
+
+
+这就是 **MoE(混合专家)** 架构的威力——模型很大,但每次只调用最相关的"专家"来回答问题,**用不到 5% 的计算量实现接近全量模型的效果**。
+
+更关键的是,Qwen3.5 在 MoE 的基础上做了两个创新:
+
+1. **线性注意力(Gated Delta Networks)**:大幅降低长文本处理的计算开销
+2. **原生多模态预训练**:从一开始就用文本+图像+视频混合训练,不是后期拼接
+
+结果就是:**不到 40% 的参数量,达到了上一代万亿参数 Qwen3-Max 的性能水平**。
+
+### 3.2 跑分数据全面开花
+
+来看硬核数据:
+
+#### 综合能力对比
+
+| 基准测试 | Qwen3.5 | GPT-5.2 | Claude 4.5 | 说明 |
+|---------|---------|---------|-----------|------|
+| MMLU-Pro | **87.8** | 86.5 | — | 知识推理,超越 GPT-5.2 |
+| GPQA | **88.4** | — | 87.9 | 博士级难题,超越 Claude 4.5 |
+| AIME 2026 | 91.3 | **96.7** | 93.3 | 数学竞赛,仍有差距 |
+| IFBench | **76.5** | 75.4 | 58.0 | 指令遵循,大幅领先 |
+
+#### LMArena 细分排名
+
+| 维度 | 全球排名 | 中国排名 |
+|------|---------|---------|
+| 综合(无风格控制) | 第 6 | 第 1 |
+| 数学能力 | 第 5 | 第 1 |
+| 专家文本 | 第 10 | 第 1 |
+
+
+
+### 3.3 原生多模态:不只是看图,还能看视频
+
+Qwen3.5 的多模态能力不是"加个视觉模块"那么简单。它从预训练阶段就把视觉和文本放在一起训练,属于**早期融合(Early Fusion)**。
+
+能做什么:
+
+- **图像理解**:读文档、看图表、识别 UI 界面
+- **视频分析**:支持最长 **2 小时** 的视频直接输入
+- **GUI 智能体**:自主操作手机和电脑界面完成任务
+- **支持 201 种语言**
+
+在多模态推理、视觉问答、文本识别、空间智能、视频理解等评测中,Qwen3.5 均拿到了开源模型的最佳成绩。
+
+---
+
+## 四、价格屠夫:百万 Token 只要 0.8 元
+
+性能强是一方面,但 Qwen3.5 真正让人兴奋的,是它的**价格和开源策略**。
+
+### API 定价对比
+
+| 模型 | 百万输入 Token 价格 | 百万输出 Token 价格 |
+|------|-------------------|-------------------|
+| GPT-5.4 | ≈ ¥15 | ≈ ¥60 |
+| Claude Opus 4.6 | ≈ ¥15 | ≈ ¥75 |
+| Gemini 3 Pro | ≈ ¥14.4 | ≈ ¥57.6 |
+| **Qwen3.5-Plus** | **¥0.8** | **¥— (极低)** |
+
+
+
+没看错,**Qwen3.5-Plus 的输入价格是 Gemini 3 Pro 的 1/18**。
+
+### 部署效率
+
+和上一代 Qwen3-Max 相比:
+
+- 显存占用**降低 60%**
+- 推理吞吐量**最高提升 19 倍**
+
+这意味着同样的 GPU 资源,能服务更多用户,成本进一步摊薄。
+
+### 开源优势
+
+Qwen3.5 全系列开源,这意味着:
+
+- **本地部署**:可以在自己的服务器上跑,数据不出境
+- **可微调**:针对特定业务场景定制模型
+- **无 API 依赖**:不用担心服务商涨价或停服
+- **社区生态**:Ollama、vLLM、ModelScope 等工具链全面支持
+
+对于企业用户来说,这可能比排行榜上的分数更有吸引力。
+
+---
+
+## 五、普通人怎么用?
+
+说了这么多技术细节,落到实际使用上,有几个入口可以体验 Qwen3.5:
+
+### 5.1 最简单:通义千问官网
+
+直接访问 [tongyi.aliyun.com](https://tongyi.aliyun.com) 或者下载通义千问 App,就能免费对话体验。
+
+### 5.2 开发者:阿里云百炼 API
+
+通过阿里云百炼平台接入 API,适合需要集成到自己产品里的开发者。定价极具竞争力,还有新用户免费额度。
+
+### 5.3 本地部署:中等规模模型
+
+如果你有一张不错的显卡,可以用 Ollama 或 vLLM 部署 Qwen3.5 的中等规模模型(4B、9B、27B):
+
+```bash
+# 以 Ollama 为例
+ollama run qwen3.5:27b
+```
+
+2B 和 4B 模型甚至可以在手机端运行,适合端侧部署。
+
+### 5.4 适合什么场景?
+
+| 场景 | 推荐模型 | 说明 |
+|------|---------|------|
+| 日常对话、写作 | Qwen3.5-Plus | 性价比最高 |
+| 编程辅助 | Qwen3.5-Max | 代码能力强 |
+| 图片/文档分析 | Qwen3.5(多模态) | 原生视觉理解 |
+| 视频内容理解 | Qwen3.5(多模态) | 支持 2 小时视频 |
+| 企业私有化部署 | Qwen3.5-27B 开源版 | 数据不出境 |
+| 手机端 AI 助手 | Qwen3.5-2B | 轻量本地运行 |
+
+
+
+---
+
+## 写在最后:里程碑,但保持清醒
+
+Qwen3.5-Max-Preview 在 LMArena 上的表现,确实是中国大模型发展的一个**里程碑时刻**。
+
+从两年前的追赶,到今天能在全球最权威的盲测平台上超越 GPT-5.4、比肩 Gemini 和 Claude——这个进步是实实在在的。
+
+但也要保持清醒:
+
+1. **这是预览版**,正式版的表现还需要观察
+2. **LMArena 测的是综合对话体验**,在编程(SWE-Bench)、数学(AIME)等单项上,Qwen3.5 和顶尖模型还有差距
+3. **排行榜分数 ≠ 实际体验**,真正好不好用,还得自己试
+
+但不管怎么说,**中国终于有了一个能在全球顶尖梯队里站稳脚跟的大模型**。而且它还是开源的、便宜的、可以本地部署的。
+
+这对整个中国 AI 生态来说,意义重大。
+
+期待 Qwen3.5 正式版的表现。
+
+---
+
+> **如果这篇文章对你有帮助,欢迎点赞、收藏、转发,你的支持是我持续输出的最大动力。**
+>
+> 关注「老邓唠AI」,每周带你拆解 AI 圈最值得关注的大事。
+
+---
+
+**参考来源:**
+
+- [LMArena 官方排行榜](https://arena.ai/leaderboard/text)
+- [阿里云通义千问官网](https://www.aliyun.com/product/tongyi)
+- [Qwen3.5 技术博客](https://developer.aliyun.com/article/1712860)
+- [IT之家:阿里通义千问 3.5-Max-Preview 首发亮相](https://www.ithome.com/0/930/834.htm)
+- [量子位:Qwen3.5-Max 预览版首度亮相](https://www.qbitai.com/2026/03/389610.html)
diff --git a/articles/007/benchmark-comparison.png b/articles/007/benchmark-comparison.png
new file mode 100644
index 0000000..d433a1d
Binary files /dev/null and b/articles/007/benchmark-comparison.png differ
diff --git a/articles/007/cover.png b/articles/007/cover.png
new file mode 100644
index 0000000..b37d361
Binary files /dev/null and b/articles/007/cover.png differ
diff --git a/articles/007/cover_raw.png b/articles/007/cover_raw.png
new file mode 100644
index 0000000..d8ef64c
Binary files /dev/null and b/articles/007/cover_raw.png differ
diff --git a/articles/007/diagrams/benchmark-comparison.html b/articles/007/diagrams/benchmark-comparison.html
new file mode 100644
index 0000000..a512517
--- /dev/null
+++ b/articles/007/diagrams/benchmark-comparison.html
@@ -0,0 +1,69 @@
+
+
+
+
+
+
+
+
+
+
diff --git a/articles/007/diagrams/lmarena-mechanism.html b/articles/007/diagrams/lmarena-mechanism.html
new file mode 100644
index 0000000..326d322
--- /dev/null
+++ b/articles/007/diagrams/lmarena-mechanism.html
@@ -0,0 +1,51 @@
+
+
+
+
+
+
+
+
+
LMArena 评测机制:全球用户当裁判
+
+
+
👤
+
用户提问
+
用户输入一个真实问题,系统随机分配两个模型
+
+
→
+
+
🤖🤖
+
匿名对战
+
两个模型同时回答,用户不知道哪个是谁
+
+
→
+
+
👆
+
真人盲测
+
用户根据回答质量投票选出更好的那个
+
+
→
+
+
📊
+
ELO 评分
+
采用国际象棋 ELO 积分系统,胜率越高分数越高
+
+
+
截至 2026 年 3 月,已累计 563 万+ 次投票,覆盖 333 个模型
+
+
Qwen3.5 MoE 混合专家架构
+
+
+
+
↓ 仅激活
+
+
170 亿
+
激活参数 (A17B) ≈ 4.3%
+
+
+
+
路由器
Router
+
专家 1
+
专家 2
+
专家 3
+
专家 4
+
专家 5
+
专家 6
+
专家 7
+
专家 8
+
+
+
+
线性注意力
+
Gated Delta Networks,大幅降低长文本处理的计算开销
+
+
+
原生多模态预训练
+
文本 + 图像 + 视频混合训练,非后期拼接
+
+
+
推理效率提升
+
显存降低 60%,吞吐量提升最高 19 倍
+
+
+
+
不到 40% 的参数量,达到上一代万亿参数 Qwen3-Max 的性能水平
+
+
百万 Token 输入价格对比(人民币)
+
+
+
GPT-5.4
+
OpenAI
+
百万输入 Token
+
¥15
+
百万输出 ≈ ¥60
+
+
+
Claude Opus 4.6
+
Anthropic
+
百万输入 Token
+
¥15
+
百万输出 ≈ ¥75
+
+
+
Gemini 3 Pro
+
Google
+
百万输入 Token
+
¥14.4
+
百万输出 ≈ ¥57.6
+
+
+
Qwen3.5-Plus
+
阿里
+
百万输入 Token
+
¥0.8
+
价格仅为 1/18
+
+
+
同等质量下,Qwen3.5-Plus 成本不到国际顶尖模型的 1/18
+
+
Qwen3.5 使用场景推荐
+
+
+
💬
+
日常对话 & 写作
+
Qwen3.5-Plus
+
性价比最高,适合日常聊天、文案创作、知识问答
+
+
+
💻
+
编程辅助
+
Qwen3.5-Max
+
代码能力强,支持多语言编程、代码审查、调试
+
+
+
🖼️
+
图片 / 文档分析
+
Qwen3.5 多模态
+
原生视觉理解,读文档、看图表、识别 UI
+
+
+
🎬
+
视频内容理解
+
Qwen3.5 多模态
+
支持最长 2 小时视频直接输入分析
+
+
+
🏢
+
企业私有化部署
+
Qwen3.5-27B 开源版
+
数据不出境,可微调定制,无 API 依赖
+
+
+
📱
+
手机端 AI 助手
+
Qwen3.5-2B
+
轻量本地运行,离线可用,隐私安全
+
+
+