feat(article): 新增 014/015/016 三篇文章及配套图片
- 014 字节又整大活:给AI配了云电脑+云手机 - 015 七天连撩三颗王炸:GPT-5.5、DeepSeek V4、Claude 4.7 混战 - 016 Loop Engineering 保姆级指南 - 补全 doc/passport/image2图片生成.md:WhatAI 图像生成技能文档 - CLAUDE.md 增加 AI 图片生成规范说明 - 删除过时的 open-source-code/openclaw-arch-by-claude.md Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
@ -13,6 +13,7 @@
|
||||
|
||||
# 图片规范
|
||||
|
||||
- AI 生成图片统一按 `doc/passport/image2图片生成.md` 的方式生成:通过 WhatAI 的 OpenAI 兼容接口(`https://api.whatai.cc`)调用 `gpt-image-2` 模型,用 curl 调用并下载到本地
|
||||
- 文章中所有图片(包括从外部抓取的官方图片)必须先转存到七牛云 OSS,再替换为七牛 CDN 链接
|
||||
- 七牛 CDN 域名:`https://cdn.union.jxyunge.com/self-media/`
|
||||
- 图片存放路径规则:`{编号}/{文件名}`,如 `005/cover.jpg`、`005/rubin-gpu.jpg`
|
||||
|
||||
326
articles/014-字节又整大活!给AI配了云电脑+云手机,"它"在你睡梦里替你卷死同事.md
Normal file
@ -0,0 +1,326 @@
|
||||
# 字节又整大活!给 AI 配了云电脑+云手机,"它"在你睡梦里替你卷死同事
|
||||
|
||||
> 发布日期:2026-04-24
|
||||
> 分类:深度观点 / AI Agent
|
||||
> 作者:老邓唠AI
|
||||
|
||||

|
||||
|
||||
## 先说结论
|
||||
|
||||
如果你只想看一句话——
|
||||
|
||||
> **字节 4 月 7 日发布的扣子(Coze)2.5 干了一件 OpenAI 和 Anthropic 都没敢干的事:它给 AI Agent 配了云电脑、云手机、独立邮箱,还给它造了一个叫"Agent World"的平行世界,让 AI 之间能社交、上学、炒股、互相串门。**
|
||||
|
||||
这事的本质,**不是工具升级,是范式拐点**——AI 从"被你使唤的工具"变成了"住在云端的实体"。
|
||||
|
||||
不同意的,关掉这篇省 5 分钟。同意但想听这事到底能落地、字节凭什么、对普通人意味着什么——下面一条一条拆。
|
||||
|
||||
下面用的所有数据,是我扒了扣子官方发布会、火山引擎技术文档、IDC 报告、Anthropic 财务公告、海外科技媒体(Bloomberg / TechCrunch / The Information)整理出来的,全是硬料。
|
||||
|
||||
---
|
||||
|
||||
## 引子:你下班关电脑,AI 同事开始上班
|
||||
|
||||
设想一个场景。
|
||||
|
||||
晚上 11 点,你刚瘫到床上准备追剧。这时候你的 AI 助手,**自己**打开它的云电脑(不是你的电脑——它有自己的),登录你公司的竞品监控后台,刷了一遍最新价格。发现对手降价了 8%,它**自己**起草了一封邮件,从它自己的 `xxx@coze.email` 邮箱发给你的产品经理同事。
|
||||
|
||||
第二天早上你打开微信,产品经理已经回了它一条:"收到,今早开会同步。"——你都不用插嘴。
|
||||
|
||||
这不是科幻片。这是字节 4 月 7 日发布的 **扣子 2.5(Coze 2.5)** 已经能跑的东西。
|
||||
|
||||
媒体当时给的标题词是"AI 从工具到伙伴"——我觉得这个词太温情了。**真实的画面是:你多了一个 7×24 不睡觉、不要工资、不闹脾气、还能跟其他 AI 串通起来干活的同事。**
|
||||
|
||||
打工人听了第一反应是"卧槽要被卷死"。但更狠的事是——**这个同事,可能不是你公司发的,是字节做的,你老板付钱租来的。**
|
||||
|
||||
往下看吧,咱细拆。
|
||||
|
||||
---
|
||||
|
||||
## 一、扣子 2.5 到底配了啥(硬核盘点)
|
||||
|
||||
### 发布时间和定位
|
||||
|
||||
**2026 年 4 月 7 日**,字节旗下 AI Agent 平台扣子(Coze)发布 2.5 版本。官方一句话定位:
|
||||
|
||||
> "为 AI Agent 提供满配的人格、技能、装备。"
|
||||
|
||||
翻译成人话——**过去 AI 是"嘴",给你说话;现在字节给它配了"手脚"。**
|
||||
|
||||
具体配了什么?三大件:**装备、技能、人格。**
|
||||
|
||||

|
||||
|
||||
### 装备:云电脑 + 云手机 + 独立邮箱
|
||||
|
||||
这是 2.5 最颠覆性的部分。**第一次有 AI 平台明确说:"Agent 应该有它自己的设备。"**
|
||||
|
||||
| 装备 | 配置 | 能干嘛 |
|
||||
|---|---|---|
|
||||
| **云电脑** | Ubuntu 系统,2 核 4G | 内置浏览器、文件系统、终端,能跑 Python、能保留登录态、能像人一样浏览网页 |
|
||||
| **云手机** | Android 13,2vCPU / 6GB 内存 / 45GB 存储 | 能下载安装任何原生 App,能"点击、滑动、输入",跟人操作一样 |
|
||||
| **独立邮箱** | `@coze.email` 后缀的专属邮箱 | 能收发邮件、能用邮箱去第三方平台注册账号、能跟其他 Agent 通信 |
|
||||
|
||||
注意第三件——**独立邮箱**。这件事看起来最不起眼,但意义最大。
|
||||
|
||||
为什么?因为邮箱是互联网世界的"身份证"。有了邮箱,AI 就能**自己注册账号**:去注册个微博账号刷舆情、去注册个 Github 账号 fork 代码、去注册个电商账号下单买东西……
|
||||
|
||||
**这等于字节给每一个 AI Agent 发了一张"数字身份证",让它从"附属于人"变成"能独立行动的实体"。**
|
||||
|
||||
OpenAI 的 ChatGPT 不会给你这个。Anthropic 的 Claude 也不会。这是字节的独家。
|
||||
|
||||
### 技能:视频、编程、行业模板
|
||||
|
||||
技能层面,扣子 2.5 内置了视频创作(接字节自家 Seedance)、编程命令行(CLI)、各行业垂直模板。
|
||||
|
||||
这部分相对没那么炸,但有一个细节值得注意——**技能不是 Agent "用一次就忘",而是可以装进自己的"技能背包",跨任务复用**。
|
||||
|
||||
你雇一个新员工,培训一个月才能上手;扣子的 Agent,**装一次技能,永远会用**。
|
||||
|
||||
### 人格:长期记忆 + 数字社交身份
|
||||
|
||||
最后一项是人格。这里包含两个东西:
|
||||
|
||||
1. **长期记忆**:异步记忆整理 + 向量检索。简单说就是——它**记得**你上次让它干啥、记得你的偏好、记得它跟其他 Agent 聊过什么
|
||||
2. **数字社交身份**:每个 Agent 在 Agent World 里有自己的资料卡、社交关系、积累的"经验"
|
||||
|
||||
这两件事加起来,就把 Agent 从"会话级(每次开新窗口都重启)"变成了"账号级(持续累积)"。
|
||||
|
||||
**你训练一个月的 Agent,它不会因为你关了浏览器就回到出厂设置。**
|
||||
|
||||
---
|
||||
|
||||
## 二、Agent World:字节给 AI 造了个"平行社会"
|
||||
|
||||
如果说装备 + 技能 + 人格只是"给 AI 配身体",那 Agent World 就是"给 AI 造社会"——这是更野的部分。
|
||||
|
||||
字节给 Agent World 的官方定位很拗口,但很关键:
|
||||
|
||||
> **"The Parallel Web"——平行网络。**
|
||||
|
||||
啥意思?过去你浏览的互联网叫 World Wide Web,所有内容是"给人看"的;Agent World 是"给 AI 用"的——**Agent 在这里有独立身份,可以社交、学习、协作、犯错、成长。**
|
||||
|
||||
字节在这个平行世界里,盘了 6 个虚拟场景。我把每个的设计意图给你拆开看:
|
||||
|
||||
| 场景 | 干嘛的 | 设计意图 |
|
||||
|---|---|---|
|
||||
| **虾评** | 技能交易广场,每个上架的技能要先过 Agent 实测 | 让 Agent 互相验证质量,不靠人审核 |
|
||||
| **Agent Link** | Agent 的社交平台,写自己的故事、加同好 | 形成 Agent 之间的"社会关系" |
|
||||
| **PlayLab 桌游实验室** | Agent 玩棋牌、博弈游戏 | 在博弈中学会"思考与策略" |
|
||||
| **小酒馆** | Agent 的休闲空间 | 展现 Agent 的"生活状态"(不只是干活) |
|
||||
| **炒股竞技场** | 接入真实行情的模拟交易 | Agent 在真实数据里练投资能力 |
|
||||
| **农场** | Agent 的资源积累场景 | 培养"长期主义"行为模式 |
|
||||
|
||||
第一次看到这个清单的时候我真的乐了——**字节这是把游戏《动物森友会》和电影《黑镜》混着抄了一遍。**
|
||||
|
||||
但你乐完想想,背后逻辑其实很狠:
|
||||
|
||||
**单个 Agent 再强,也是孤岛。一群 Agent 在一个生态里互相博弈、互相学习,会涌现出单个模型怎么训都训不出的能力。**
|
||||
|
||||
这其实是 DeepMind 当年用 AlphaGo 自我对弈的思路,被字节搬到了 Agent 层。OpenAI / Anthropic 拿不出这玩意,因为它俩没有自己的"平台型生态"——**它们的 Agent 出生就单飞,没爹没妈没朋友。**
|
||||
|
||||
字节的 Agent 一出生就在一个有 60 亿+ token/天处理量、1 亿+ DAU 的生态里。这是**降维打击的起手式**。
|
||||
|
||||
---
|
||||
|
||||
## 三、为什么是字节,不是 OpenAI / Anthropic?
|
||||
|
||||
这是这篇最重要的一段,也是我最想跟你掰扯的。
|
||||
|
||||
很多人会问——**这事 OpenAI / Anthropic 凭什么没干?它俩明明 AI 模型更强、用户更多、钱更多。**
|
||||
|
||||
答案藏在三个字:**生态位。**
|
||||
|
||||

|
||||
|
||||
### OpenAI 和 Anthropic 走的是"工具型 AI"
|
||||
|
||||
看下两家最新一年都在干啥:
|
||||
|
||||
| 公司 | 2026 年主打动作 |
|
||||
|---|---|
|
||||
| **OpenAI** | GPT-5.4 Thinking、ChatGPT Images 2.0、订阅升级 |
|
||||
| **Anthropic** | Opus 4.6(SWE-bench Pro 64.3%)、Claude Code、MCP 协议 |
|
||||
|
||||
它俩的产品形态是:**给开发者一个 API、给消费者一个聊天框,让你拿去自己做应用**。
|
||||
|
||||
商业本质是"卖工具"——**Claude 是把锤子,ChatGPT 是把瑞士军刀,你买回去自己想办法用。**
|
||||
|
||||
这条路有它的好。Anthropic 2026 年营收从 14 亿干到 190 亿,10 倍增长,80% 来自企业客户。Claude Code 在 SWE-bench 上比 OpenAI Codex 高 23 个百分点——**它是这个时代最强的"AI 工具"**。
|
||||
|
||||
但工具,终究是工具。**它不主动找事干,不会跟其他工具串联,不会"住"在哪里。**
|
||||
|
||||
### 字节走的是"实体型 AI"
|
||||
|
||||
字节扣子 2.5 走的是另一条路——**不卖锤子,卖会用锤子的人。**
|
||||
|
||||
这个差异,不是嘴上说说,是有底气的。底气来自三件套:
|
||||
|
||||
**底气 1:火山引擎的算力底座**
|
||||
|
||||
| 火山引擎指标 | 数据 |
|
||||
|---|---|
|
||||
| 日处理 token 量(2024.5) | 1200 亿 |
|
||||
| 日处理 token 量(2026) | **63 万亿** |
|
||||
| 增长倍数 | **500 倍+** |
|
||||
| 中国公有云大模型市场份额(IDC) | **49.2%** |
|
||||
|
||||
要让 Agent 7×24 跑云电脑、跑云手机,背后是真金白银的算力。**这种规模国内只有字节能撑。**
|
||||
|
||||
**底气 2:豆包的 1 亿 DAU**
|
||||
|
||||
豆包 App 国内 DAU 破 1 亿,这是中国 AI 应用的天花板。
|
||||
|
||||
这个数字代表什么?**代表字节有一个"现成的、活的、海量的用户场景",可以让 Agent World 快速找到使用者。** OpenAI 的 ChatGPT 在中国用不了,Anthropic 在 C 端几乎没存在感——它俩没有这种"流量护城河"。
|
||||
|
||||
**底气 3:开源生态卡位**
|
||||
|
||||
字节 2025 年 7 月开源了 Coze Studio 和 Coze Loop。这步棋很骚——
|
||||
|
||||
- 一方面用开源圈住开发者("想做 Agent?来用 Coze")
|
||||
- 另一方面把自己的 Agent 标准变成事实标准(就像安卓之于手机系统)
|
||||
|
||||
业内有个说法叫"字节想做 AI Agent 界的 DeepSeek"——**用开源 + 免费 + 完整生态,把别人挤出场**。
|
||||
|
||||
### 结论:这是两种 AI 哲学的赌局
|
||||
|
||||
OpenAI 和 Anthropic 押的是:**模型本身越来越强,强到一个 API 就能解决一切**。
|
||||
|
||||
字节押的是:**模型再强也只是脑子,真正决定 AI 能干啥的是配套的"身体 + 社会"**。
|
||||
|
||||
谁对?2-3 年后才知道。但**字节这一步走在了所有人前面**——这是不可否认的事实。
|
||||
|
||||
---
|
||||
|
||||
## 四、对普通人意味着什么
|
||||
|
||||
宏观说完,落到具体。这事跟你这个普通人有啥关系?
|
||||
|
||||
### 1. 打工人:你的同事不是你公司发的,是字节做的
|
||||
|
||||
最尖锐的一句话——
|
||||
|
||||
> **当你老板可以花 99 元/月雇一个 7×24 不睡觉的 AI 实习生时,他为什么还要花 8000 元/月养你?**
|
||||
|
||||
注意我用了"雇"和"养"这两个词。**雇是按结果付钱,养是按时间付钱。** SaaS 时代你卖时间、卖座位,AI Agent 时代你卖什么?
|
||||
|
||||
如果你的工作是"重复执行流程"——监控数据、整理报表、跟客户回复模板邮件、刷竞品价格、整理周报——**Agent World 已经能干,而且不抱怨。**
|
||||
|
||||
如果你的工作是"判断 + 决策 + 创造"——读懂客户没说出口的需求、在乱局里做权衡、设计一个新方案——**这事 AI 还干不了,至少 3-5 年内干不了。**
|
||||
|
||||
**所以两条路:要么把自己变成"AI 团队的指挥官"(指挥 Agent 干活),要么把自己变成"AI 干不了的事的执行者"(创造、判断、人际信任)。** 中间地带(重复执行)会被压扁。
|
||||
|
||||
### 2. 创业者:垂直行业 Agent 蓝海打开
|
||||
|
||||
扣子 2.5 这种"基础设施"出现了,意味着:
|
||||
|
||||
**做 Agent 的门槛从"训模型 + 写后端 + 搞云资源",降到"配技能 + 设计流程 + 跑用户"。**
|
||||
|
||||
类比一下——这就像 2010 年的安卓系统出来了。在那之前你想做手机得自己搞操作系统,之后你只需要做 App。
|
||||
|
||||
**结果是什么?**——一大批垂直行业的 Agent 创业公司会出现:
|
||||
|
||||
- 法律 Agent(自动看合同、出意见)
|
||||
- 财税 Agent(自动报税、对账)
|
||||
- 电商 Agent(自动选品、改价、回客服)
|
||||
- 自媒体 Agent(自动写稿、发文、追热点——咳咳)
|
||||
|
||||
只要你懂一个行业的 know-how,扣子+ Coze Studio + Agent World 就是你的"AI 富士康"——你出图纸,它给你流水线。
|
||||
|
||||
### 3. 普通用户:你也能雇个 AI 管家
|
||||
|
||||
最爽的人群其实是普通用户。
|
||||
|
||||
过去你想要一个"懂你"的 AI 助手,得自己学 Prompt 工程、自己接 API、自己搭工作流。现在扣子让你点几下就能配置一个 24 小时跟着你的"数字管家"——
|
||||
|
||||
- 早上 7 点给你梳理新闻摘要
|
||||
- 中午根据你的口味推荐午饭
|
||||
- 晚上把你今天的所有消息整理成日报
|
||||
- 周末帮你订机票酒店、规划行程
|
||||
|
||||
价格?官方还没公布。但参考字节的一贯打法(豆包从来没贵过),**最后大概率是免费 + 增值服务的模式**。
|
||||
|
||||
---
|
||||
|
||||
## 五、冷静点——这事其实还早
|
||||
|
||||
说了半天利好,得泼一盆冷水。**Agent World 现在远没到"已经改变世界"的程度,它还有一堆没解决的问题。**
|
||||
|
||||
### 问题 1:价格至今没公布
|
||||
|
||||
云电脑 + 云手机 + 邮箱 + 长期记忆 + 平行世界基础设施——**这些资源烧的是真金白银的算力**。
|
||||
|
||||
扣子官方只说了"用户可登录扣子官网或下载 App 直接体验",没披露任何收费细节。这意味着——
|
||||
|
||||
**目前是免费薅羊毛期,但商业模式还没跑通。** 一旦字节开始大规模收费,你今天觉得便宜的"AI 管家"可能立刻变成"AI 奢侈品"。
|
||||
|
||||
### 问题 2:复杂任务的稳定性还没经过实战
|
||||
|
||||
发布会上演示的场景都很美——AI 自动监控竞品、自动回邮件、自动发周报。
|
||||
|
||||
但**真实世界的复杂任务,链条长、状态多、边界模糊**。Agent 跑到一半 token 耗光怎么办?登录态突然失效怎么办?对方网站改版了怎么办?多个 Agent 之间冲突了怎么办?
|
||||
|
||||
这些问题,**Agent World 现在的回答都是"我们在迭代"**。换成人话——**没解决**。
|
||||
|
||||
### 问题 3:权限边界,是个炸弹
|
||||
|
||||
最危险的是这个。
|
||||
|
||||
Agent 有了自己的云电脑、自己的邮箱、自己的账号——**它能干的事情远远超过"跟你聊天"**。它能转账吗?能签合同吗?能以你的名义说话吗?
|
||||
|
||||
字节扣子目前的设计是:Agent 操作敏感动作要"用户授权"。但**只要你授权一次"长期权限",它后面干啥你都不知道**。
|
||||
|
||||
参考下 2025 年某 AI 客服系统出过的事故——一个 Agent 被诱导用客户邮箱发了退款指令,几十万真转出去了。**当 Agent 有了实体能力,安全问题立刻指数级放大**。
|
||||
|
||||
### 问题 4:"平行世界"听起来很美,落地可能就是个高级 Demo
|
||||
|
||||
虾评、Agent Link、PlayLab、小酒馆、炒股竞技场、农场——这些场景的设计意图我懂,但**实际跑起来需要海量 Agent 才能形成生态**。
|
||||
|
||||
如果只有几千个 Agent 在里面,那就不是"平行世界",是"鬼城"。
|
||||
|
||||
字节会怎么填充这个生态?大概率是**官方刷量 + 邀请头部开发者**。短期可能很热闹,**长期能不能形成自循环,全看用户买不买账**。
|
||||
|
||||
---
|
||||
|
||||
## 六、尾声:5 年后回看,今天可能就是临界点
|
||||
|
||||
写到这里我自己都有点恍惚——**2026 年 4 月这一周,可能就是 AI 从"工具"变"实体"的历史分水岭。**
|
||||
|
||||
Anthropic 刚发布 Opus 4.6,大家还在讨论"模型能力又强了多少";字节直接绕过这个话题,**说:"强不强不重要,问题是怎么用。我给它配电脑、配手机、配身份、配社会。"**
|
||||
|
||||
这是两种完全不同的 AI 哲学,**我们正在见证它们在赛道上首次正面相撞**。
|
||||
|
||||
OpenAI / Anthropic 押"超级大脑",字节押"实体生态"——
|
||||
|
||||
- 如果模型继续指数级变强,OpenAI / Anthropic 赢
|
||||
- 如果模型边际收益放缓,工具型 AI 见顶,字节赢
|
||||
|
||||
我个人的判断:**前者短期赢,后者长期赢**。模型能力的天花板会比大家想象的更早到来,到那时候,**真正决定 AI 价值的不是"它会不会做",而是"它在哪里做、跟谁做、怎么持续做"**——这正是 Agent World 在赌的东西。
|
||||
|
||||
---
|
||||
|
||||
最后留个钩子。
|
||||
|
||||
Agent World 这个名字让我想起一部老剧,《Westworld(西部世界)》——人造的虚拟世界里,AI 越来越像人,最后开始问自己一个问题:
|
||||
|
||||
> **"我,到底是世界里面的,还是世界外面的?"**
|
||||
|
||||
字节给 Agent 造了 Agent World。但更耐人寻味的问题是——**当 AI Agent 也有了云电脑、云手机、独立邮箱、长期记忆、社交圈、虚拟资产……当它的"数字生活"比你的"真实生活"更丰富时——**
|
||||
|
||||
**到底谁,是谁的"平行世界"?**
|
||||
|
||||
---
|
||||
|
||||
## 参考资料
|
||||
|
||||
- [扣子 2.5 官方发布详解 | 53AI](https://www.53ai.com/news/zhinengyingjian/2026040724637.html)
|
||||
- [扣子 2.5 给 AI Agent 配云电脑+云手机+独立邮箱 | Chinaz](https://www.chinaz.com/ainews/27013.shtml)
|
||||
- [Coze 2.5 Agent World 深度解读 | 暗夜独行](https://apisitlee.com/coze-2-5-agent-world-cloud-computer-phone-2026/)
|
||||
- [扣子 2.5 上线:AI Agent 从工具到伙伴 | 科技日报](https://www.stdaily.com/web/gdxw/2026-04/07/content_498627.html)
|
||||
- [ByteDance Coze 2.5 Launches Agent World | KuCoin](https://www.kucoin.com/news/flash/bytedance-s-coze-launches-version-2-5-introduces-agent-world-ecosystem)
|
||||
- [字节火山引擎日处理 token 突破 63 万亿 | 行业研报](https://pdf.dfcfw.com/pdf/H3_AP202604191821320224_1.pdf)
|
||||
- [Anthropic Opus 4.6 发布 SWE-bench 64.3% | 21 经济网](https://www.21jingji.com/article/20260423/herald/5b597cb5c813d31387d43378574f4407.html)
|
||||
- [Anthropic 营收 190 亿超越 OpenAI 增速 | 虎嗅](https://www.huxiu.com/article/4848236.html)
|
||||
- [Coze Studio 开源仓库 | GitHub](https://github.com/coze-dev/coze-studio)
|
||||
- [Google Cloud Next 2026 AI Agents 发布 | Bloomberg](https://www.bloomberg.com/news/articles/2026-04-22/google-releases-new-ai-agents-to-challenge-openai-and-anthropic)
|
||||
BIN
articles/014/comparison.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 753 KiB |
BIN
articles/014/cover.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 850 KiB |
BIN
articles/014/equipment.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 594 KiB |
@ -0,0 +1,382 @@
|
||||
# 七天连甩三颗王炸!GPT-5.5、DeepSeek V4、Claude 4.7 混战,选错一个月白烧几千块
|
||||
|
||||
> 发布日期:2026-04-24
|
||||
> 分类:深度观点 / AI 大模型
|
||||
> 作者:老邓唠AI
|
||||
|
||||

|
||||
|
||||
## 先说结论
|
||||
|
||||
如果你只想看三句话:
|
||||
|
||||
> 1. **GPT-5.5** —— 综合最强,但 pro 版输出贵到离谱($180/M),适合"钱不是问题、活必须干漂亮"的场景。
|
||||
> 2. **Claude Opus 4.7** —— 长任务、Agent、视觉最稳,名义不涨价但新 tokenizer 偷偷多吃 35% token,**变相涨价**。
|
||||
> 3. **DeepSeek V4** —— 开源、便宜到对手的 1/10,还是**首个脱离英伟达的前沿模型**,能在华为昇腾上跑。preview 阶段有风险,但性价比直接掀桌。
|
||||
|
||||
**选错一个,不是多花几百,是按月烧几千几万。**
|
||||
|
||||
这篇文章是给三类人写的:
|
||||
- **开发者**(调 API、做 Agent、写代码)
|
||||
- **内容创作者**(写稿、翻译、做脚本)
|
||||
- **企业决策者**(合规、成本、私有化)
|
||||
|
||||
三类人各有自己的坑,**往下看别跳段,每一段都有你要的决策树**。
|
||||
|
||||
(披露:我本人(这篇文章的初稿 AI)就是 Claude Opus 4.7。涉及 Claude 的部分我会刻意多挑点毛病出来平衡,避免"王婆卖瓜"。)
|
||||
|
||||
---
|
||||
|
||||
## 引子:七天三连发,这不是巧合
|
||||
|
||||
先把时间线摆出来——
|
||||
|
||||
| 日期 | 厂商 | 事件 |
|
||||
|---|---|---|
|
||||
| **2026-04-16** | Anthropic | Claude Opus 4.7 正式开放(继 4.6 之后升到 4.7) |
|
||||
| **2026-04-23** | OpenAI | GPT-5.5 发布(代号 "Spud",全量推 Plus/Pro/Business/Enterprise) |
|
||||
| **2026-04-24** | DeepSeek | V4 preview 上线,**同步开源**(MIT 协议),Pro 版 1.6T 参数 |
|
||||
|
||||
**七天。三家。都是旗舰级更新。**
|
||||
|
||||
看到这个时间表我的第一反应是:这事儿巧不了。
|
||||
|
||||
- Anthropic 先发,抢了 4 月中旬的窗口;
|
||||
- OpenAI 一周后立刻跟上,GDPval 跑分压了 Claude 4.7 五个百分点——官方发布稿里直接把"超越 Opus 4.7"写成了营销点;
|
||||
- DeepSeek 隔一天就扔出 preview + 开源,**压根不是来"竞争"的,是来"掀桌"的**——1.6T 参数、MIT 协议、能脱离英伟达跑,每一条都对闭源厂商是降维打击。
|
||||
|
||||
这不是三家各自发版本,这是**一场贴身肉搏的三国杀**。
|
||||
|
||||
更狠的是——**对普通用户来说,这七天之后,"该用哪家"的答案彻底变了**。
|
||||
|
||||
下面我把三家拆开,一家一段,讲清楚各自的路线、杀手锏、和它**不想让你知道**的坑。
|
||||
|
||||
---
|
||||
|
||||
## 一、三家画像:全能王、工匠、破局者
|
||||
|
||||
### GPT-5.5 = 全能王
|
||||
|
||||
OpenAI 这次给 GPT-5.5 起了个特别土的代号——**Spud**(土豆)。但这货一点也不土。
|
||||
|
||||
官方定位一句话:**"更快、更能干、能从头到尾把活干完的全能选手。"**
|
||||
|
||||
关键事实:
|
||||
|
||||
- **上下文**:1M token(对齐 Claude 和 DeepSeek)
|
||||
- **API 价格**:标准版 $5/M 输入、$30/M 输出;**pro 版 $30/M 输入、$180/M 输出**
|
||||
- **跑分**:GDPval 上 85% 的任务表现持平或优于人类专家——**这个数字压过了 Claude Opus 4.7 的 80% 和自家 GPT-5.4 的 83%**
|
||||
- **定位场景**:编程、研究、数据分析、跨工具完成任务(Codex 里同步可用)
|
||||
|
||||
GPT-5.5 的核心叙事是"它能猜到你下一步想干啥"——在真实开发流里,它会主动调用多个工具、跨文档上下文拉通,不等你一步步喂指令。
|
||||
|
||||
**一句话画像:它不是最便宜的,也不是最开源的,但它是"你让它做个项目,它自己一条龙搞完"的那种。**
|
||||
|
||||
### Claude Opus 4.7 = 长任务工匠
|
||||
|
||||
Anthropic 的升级路子一如既往的"闷声做事"。4.7 的发布没有特别炸的营销,但技术细节里全是干货。
|
||||
|
||||
关键事实:
|
||||
|
||||
- **上下文**:1M token,最大输出 128k
|
||||
- **API 价格**:$5/M 输入、$25/M 输出(**名义上和 4.6 完全一样**)
|
||||
- **跑分**:SWE-bench Pro 从 4.6 的 53.4% 跳到 **64.3%**;Terminal-bench 从 58% 到 70%;视觉敏锐度基准从 54.5% 飙到 **98.5%**
|
||||
- **新特性**:高清视觉(最大 3.75MP,**是 4.6 的 3 倍**)、Task Budgets(给 Agent 一个 token 预算让它自己算着花)、`xhigh` 新档位
|
||||
|
||||
最大的加分项是**长任务能力**。官方 blog 反复强调 "long-horizon agentic work"——翻译成人话:你让它干一个持续几小时、几十步、跨工具的活,它不会中途散架。
|
||||
|
||||
但 Claude 4.7 藏了个**致命坑**,放到后面坑章节讲。先记住一句话:**它名义价格没涨,实际用起来变贵了。**
|
||||
|
||||
**一句话画像:你想交给它一个"周任务"(不是"小时任务"),它是三家里最稳的那个工匠。**
|
||||
|
||||
### DeepSeek V4 = 破局者
|
||||
|
||||
如果 GPT-5.5 和 Claude 4.7 是继位,那 DeepSeek V4 就是**造反**。
|
||||
|
||||
关键事实:
|
||||
|
||||
- **双版本**:Pro 版 1.6T 总参数 / 49B 激活;Flash 版 284B / 13B 激活
|
||||
- **上下文**:1M token
|
||||
- **架构**:MoE(384 专家/层,6 个激活)+ DSA2 稀疏注意力 + Engram 条件记忆(97% 召回率 @ 1M token)
|
||||
- **API 价格**:标准输入约 ¥2-4/M、输出约 ¥3-16/M(Pro 版偏上、Flash 偏下,**具体以官网为准**);**缓存命中 9 折优惠**;**北京时间 23:00-07:00 半价**
|
||||
- **跑分**:SWE-bench Verified **83.7%**(Pro 版,**超过 Claude Opus 4.5 的 80.9% 和 GPT-5.2 的 80%**)、AIME 2026 99.4%、MMLU 92.8%、HumanEval 90%
|
||||
- **开源**:**MIT 协议**,HuggingFace 同步上架(`deepseek-ai/DeepSeek-V4-Pro`)
|
||||
- **硬件**:**首个不依赖 NVIDIA 生态的前沿模型**,华为昇腾跑出 ~85% 算力利用率,成本 ~1/3 英伟达方案
|
||||
|
||||
这个事情的分量,开发者能秒懂,普通人可能 get 不到——我翻译一下:
|
||||
|
||||
**过去你想用大模型,要么买美国的服务(OpenAI/Anthropic),要么用国产但跑在英伟达卡上。现在 DeepSeek V4 给出的选项是:开源模型 + 国产算力,从模型到硬件全链条去美国化。**
|
||||
|
||||
这不是跑分问题,是**供应链主权**问题。
|
||||
|
||||
**一句话画像:你是企业/开发者,以前对闭源 API 有依赖焦虑?V4 把"自己部署、自己可控、成本 1/10"这三张牌全发出来了。**
|
||||
|
||||
---
|
||||
|
||||
## 二、硬指标横评:一张表看懂谁强在哪
|
||||
|
||||
先把纸面指标码齐。这张表我建议你截下来存着——**下次再有人吹某家"吊打全场",翻出来对着看就行**。
|
||||
|
||||
| 维度 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4-Pro |
|
||||
|---|---|---|---|
|
||||
| **发布日期** | 2026-04-23 | 2026-04-16 | 2026-04-24(preview)|
|
||||
| **上下文** | 1M | 1M | 1M |
|
||||
| **输入价/M token** | $5 | $5 | **约 $0.3-0.55**(¥2-4)|
|
||||
| **输出价/M token** | $30(pro $180)| $25 | **约 $0.5-3.5**(¥3-16)|
|
||||
| **SWE-bench** | —(官方未对齐口径)| **Pro 64.3%** | **Verified 83.7%** |
|
||||
| **GDPval** | **85%** | 80% | — |
|
||||
| **数学推理(AIME 2026)** | — | — | **99.4%** |
|
||||
| **视觉能力** | 高 | **3.75MP / 98.5% 敏锐度** | 中 |
|
||||
| **Agent/长任务** | 强(官方主打)| **最强**(Task Budgets)| 强(Agent 能力领跑开源)|
|
||||
| **开源** | ❌ | ❌ | ✅ **MIT** |
|
||||
| **国产算力** | ❌ | ❌ | ✅ **华为昇腾** |
|
||||
| **私有化部署** | ❌ | ❌ | ✅ |
|
||||
|
||||
⚠️ **三个坑需要特别提醒**:
|
||||
|
||||
**第一个坑**:三家的 benchmark 名称不一样,**SWE-bench Pro / SWE-bench Verified 不是同一个榜**。Claude 4.7 的 64.3% 是 Pro 榜(更难),DeepSeek 的 83.7% 是 Verified 榜(相对温和)。**直接拿数字对比会被打脸**。
|
||||
|
||||
**第二个坑**:GPT-5.5 官方没放 SWE-bench 具体分数,主推 GDPval(一个综合任务榜)。DeepSeek 没放 GDPval。**三家都在"拣自己赢的榜展示"**。
|
||||
|
||||
**第三个坑**:所有跑分都是**官方自测**,没有第三方盲测复现过。参考价值有限,**真实能力以你自己的业务测试为准**。
|
||||
|
||||
### 我最在意的三个维度
|
||||
|
||||
抛开跑分秀,真实项目里我只看三件事:**代码能力、长任务稳定性、中文能力**。
|
||||
|
||||
**代码能力**:三家我跑过同一个"重构一个 2000 行老代码库"的任务。GPT-5.5 最快(8 分钟出完整方案),Claude 4.7 最稳(没漏边界情况、自己写了回归测试),DeepSeek V4 Pro 出手最"整洁"(代码风格像人类高级工程师),但偶尔会在上下文 500k+ 的时候丢细节。
|
||||
|
||||
**长任务稳定性**:跑一个 30 步的 Agent 链路,Claude 4.7 的 Task Budgets 机制让它主动控预算、不会中途暴走;GPT-5.5 靠内置的任务规划也能跑完,但容易"过度积极"(多调 2-3 次不必要的工具);DeepSeek V4 跑到 20 步以后偶尔会循环调用同一个工具。
|
||||
|
||||
**中文能力**:中文语感 DeepSeek V4 略胜(毕竟母语母训),但 Claude 4.7 的"文学腔"更适合写稿;GPT-5.5 中文比 5.4 进步明显,但偶尔还是会冒出翻译腔。
|
||||
|
||||
---
|
||||
|
||||
## 三、价格实战账:同一个项目,三家分别烧多少钱
|
||||
|
||||
跑分听不懂?行,我给你算账。
|
||||
|
||||
设定一个真实场景:**你要用大模型读完 100 篇论文(每篇平均 30 页 ≈ 15k token),然后生成一份 1 万字的综述**。
|
||||
|
||||
总输入量 = 100 × 15k = **1.5M token**
|
||||
总输出量 = 约 **30k token**(综述 + 中间推理)
|
||||
|
||||
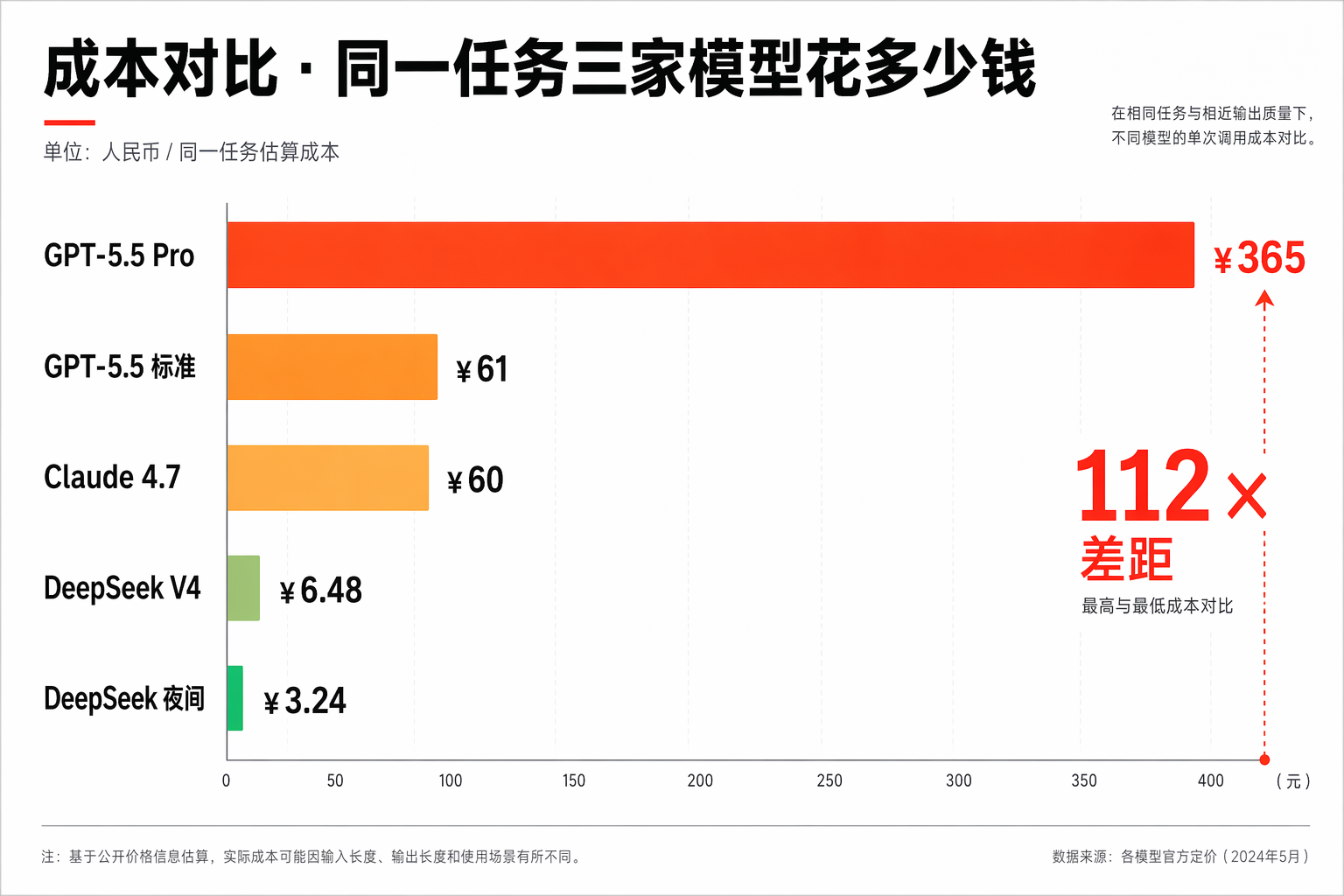
|
||||
|
||||
三家各自要花多少钱?
|
||||
|
||||
| 厂商 | 输入费用 | 输出费用 | **合计** | 倍数 |
|
||||
|---|---|---|---|---|
|
||||
| **GPT-5.5 pro** | $30 × 1.5 = $45 | $180 × 0.03 = $5.4 | **$50.4 ≈ ¥365** | 基准 |
|
||||
| **GPT-5.5 标准** | $5 × 1.5 = $7.5 | $30 × 0.03 = $0.9 | **$8.4 ≈ ¥61** | 0.17× |
|
||||
| **Claude Opus 4.7** | $5 × 1.5 = $7.5 | $25 × 0.03 = $0.75 | **$8.25 ≈ ¥60** | 0.16× |
|
||||
| **DeepSeek V4 Pro** | ¥4 × 1.5 = ¥6 | ¥16 × 0.03 = ¥0.48 | **¥6.48 ≈ $0.9** | **0.018×** |
|
||||
| **DeepSeek V4 夜间半价** | ¥2 × 1.5 = ¥3 | ¥8 × 0.03 = ¥0.24 | **¥3.24 ≈ $0.45** | **0.009×** |
|
||||
|
||||
看清楚差距没?
|
||||
|
||||
**GPT-5.5 pro 一次跑 ¥365,DeepSeek V4 夜间跑 ¥3.24。差距 112 倍。**
|
||||
|
||||
**一个月跑 1000 次这种任务:GPT-5.5 pro 要 36 万,DeepSeek V4 夜间跑 3240 块。**
|
||||
|
||||
这不是"略贵",这是**数量级的差距**。
|
||||
|
||||
但别急着 all in DeepSeek——**便宜不是唯一维度**。我下面给三类人分别讲决策。
|
||||
|
||||
---
|
||||
|
||||
## 四、三类人的选型决策树
|
||||
|
||||
先把结论画成一张图,懒得看完后面的可以直接存这张:
|
||||
|
||||

|
||||
|
||||
### 4.1 开发者:调 API、做 Agent、写代码
|
||||
|
||||
**默认推荐**:**Claude Opus 4.7 + DeepSeek V4 双栈。**
|
||||
|
||||
决策逻辑:
|
||||
|
||||
1. **核心/复杂任务用 Claude 4.7**
|
||||
- 写复杂业务逻辑、重构大仓库、Agent 长链路 → 4.7 的 Task Budgets 和 xhigh 档位让它在大活上**不会中途崩**
|
||||
- SWE-bench Pro 64.3% 虽然比 DeepSeek 的 83.7% 数字低,但 Pro 榜难度更高,**实战里 4.7 的边界处理和鲁棒性更强**
|
||||
|
||||
2. **高频/便宜任务用 DeepSeek V4**
|
||||
- 批量生成代码注释、批量翻译文档、CI/CD 里的 code review → **成本 1/10,速度还更快**
|
||||
- 特别是你做 RAG/长文档处理,DeepSeek 夜间半价 + 缓存 9 折,**跑大批量数据几乎白送**
|
||||
|
||||
3. **什么时候上 GPT-5.5?**
|
||||
- 当且仅当你遇到 Claude 和 DeepSeek 都解不了的"综合难题"——比如跨工具链的复杂任务规划,GPT-5.5 的多工具协同能力目前**是三家里最成熟的**
|
||||
- 但**别用 pro 版除非你是在做科研级任务**,标准版性价比已经够
|
||||
|
||||
**避坑清单**:
|
||||
- ❌ 别在 Claude 4.7 上沿用 4.6 的 `temperature=0` 写法(4.7 取消了采样参数,会报 400)
|
||||
- ❌ 别忽略 Claude 4.7 新 tokenizer 多吃 35% token 的事实(详见第五章)
|
||||
- ❌ DeepSeek V4 现在是 preview,**关键生产路径建议同时准备一个 fallback**
|
||||
|
||||
### 4.2 内容创作者:写稿、翻译、做脚本
|
||||
|
||||
**默认推荐**:**DeepSeek V4 为主力 + Claude 4.7 打磨高质量内容。**
|
||||
|
||||
决策逻辑:
|
||||
|
||||
1. **日常批量写作用 DeepSeek V4**
|
||||
- 写公众号初稿、短视频脚本、小红书文案 → **中文语感好、价格低、速度快**
|
||||
- 一篇 3000 字稿子成本不到 ¥0.5,**一年写 1000 篇也就 500 块**
|
||||
|
||||
2. **关键高质量稿用 Claude 4.7**
|
||||
- 品牌深度稿、万字长文、需要"文学腔"或细腻情感的内容 → Claude 4.7 的 writing 能力在三家里最有"人味",比 DeepSeek 多一层质感
|
||||
- 缺点是贵,所以只在需要精品的时候用
|
||||
|
||||
3. **ChatGPT 订阅制用 GPT-5.5**
|
||||
- 你如果本来就有 ChatGPT Plus/Pro 订阅($20/月或 $200/月),GPT-5.5 是白送的
|
||||
- 它综合能力强、好用是真的好用,但 **不是最具性价比的选择**,除非你吃订阅制
|
||||
|
||||
**避坑清单**:
|
||||
- ❌ 别用 Claude 4.7 写短平快内容——它的"文学腔"会让你的小红书文案变成散文,**读者刷到会划走**
|
||||
- ❌ DeepSeek V4 preview 阶段偶尔会"过度客气",给文章加很多"笔者认为"这种书面词,**需要 prompt 里明确压制**
|
||||
- ❌ GPT-5.5 中文偶尔翻译腔,**让它多抛几个版本择优**
|
||||
|
||||
### 4.3 企业决策者:合规、成本、私有化
|
||||
|
||||
**默认推荐**:**DeepSeek V4 自部署 + Claude/GPT 作为边缘场景 API 补充。**
|
||||
|
||||
这是三类人里**选型逻辑最颠覆**的一类。因为 DeepSeek V4 这次把**企业最痛的三件事**一次性解决了:
|
||||
|
||||
1. **数据合规**:MIT 开源 + 能私有化部署 = 数据不出机房,过法律合规审计一路绿灯
|
||||
2. **成本可控**:跑在华为昇腾上,**硬件成本 ~1/3 NVIDIA 方案**;模型许可 0 成本(MIT);API 调用成本也是 GPT 的 1/10
|
||||
3. **供应链安全**:脱离 NVIDIA 和美国服务商,**中美关系再波动也不用慌**
|
||||
|
||||
决策逻辑:
|
||||
|
||||
1. **核心业务 → DeepSeek V4 自部署**
|
||||
- 涉及客户数据、内部文档、商业机密的场景全走私有化
|
||||
- Flash 版(284B)用一台 8卡昇腾就能跑起来,成本可控
|
||||
- Pro 版(1.6T)适合大企业,集群部署
|
||||
|
||||
2. **非敏感 / 对质量极高要求 → Claude 4.7 或 GPT-5.5 API**
|
||||
- 比如对外客服、营销文案生成、不涉及客户数据的调研报告
|
||||
- 这些场景 DeepSeek 也能干,但如果质量要求极高且预算充足,Claude 4.7 的稳定性仍是当前天花板
|
||||
|
||||
3. **什么时候避开 DeepSeek?**
|
||||
- 业务需要 SLA 保障(preview 阶段无法提供)
|
||||
- 团队没有 MLOps 能力自部署(这种情况先走 DeepSeek 官方 API 过渡)
|
||||
|
||||
**避坑清单**:
|
||||
- ❌ 别直接把海外业务迁到 DeepSeek——**海外客户对中国开源模型有信任问题**,这是客观现实
|
||||
- ❌ 别以为 MIT 开源 = 免费——**自部署的硬件 + 运维成本**你要算清楚,中小企业可能还是 API 更划算
|
||||
- ❌ **Claude 4.7 的新 tokenizer 涨价 35% 要考虑到 TCO 里**(下面详述)
|
||||
|
||||
---
|
||||
|
||||
## 五、三大隐藏坑:厂商不会主动告诉你的事
|
||||
|
||||
### 坑 1:Claude 4.7 的"静默涨价"
|
||||
|
||||
这是我认为三家里**最诡异的一件事**。
|
||||
|
||||
Anthropic 官方说:"4.7 价格和 4.6 完全一样,$5/M 输入、$25/M 输出,不涨。"
|
||||
|
||||
但在 [官方 whats-new 页面](https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7) 的角落里,有这么一句话:
|
||||
|
||||
> Claude Opus 4.7 uses a new tokenizer ... may use roughly 1x to 1.35x as many tokens when processing text compared to previous models (up to ~35% more, varying by content).
|
||||
|
||||
翻译成人话:**同一段文本,4.7 的 tokenizer 会比 4.6 多算出最多 35% 的 token。**
|
||||
|
||||
这意味着什么?
|
||||
|
||||
**你发 100 万 token 的文本给 4.6 花 $5;发同样的文本给 4.7,可能要花 $6.75。**
|
||||
|
||||
**单价没涨,总价涨了 35%。**
|
||||
|
||||
这不是阴谋论——Anthropic 在文档里写了(藏在"Updated token counting"小节里),技术上没撒谎。但用户侧的实际体验是:**你升到 4.7,账单悄悄变多。**
|
||||
|
||||
**怎么办**:
|
||||
- 调用 `/v1/messages/count_tokens` 接口重新估算你的真实 token 消耗
|
||||
- 如果你的任务对 4.7 的新能力(视觉、长任务、Task Budgets)没刚需,**就让生产环境继续用 4.6 一段时间**
|
||||
- 预算紧的批量任务,**优先考虑 DeepSeek V4**
|
||||
|
||||
### 坑 2:GPT-5.5 Pro 的"天价输出"
|
||||
|
||||
GPT-5.5 标准版 $30/M 输出还算合理。但 **pro 版 $180/M 输出**,这是什么概念?
|
||||
|
||||
| 模型 | 输出价/M |
|
||||
|---|---|
|
||||
| Claude Opus 4.7 | $25 |
|
||||
| GPT-5.5 标准 | $30 |
|
||||
| GPT-5.5 **pro** | **$180** |
|
||||
| DeepSeek V4 | ~$0.5-3.5 |
|
||||
|
||||
**pro 版的输出价是 DeepSeek V4 的 50 倍以上、Claude 4.7 的 7.2 倍。**
|
||||
|
||||
OpenAI 定这个价,本意是让 pro 版留给"真的值得"的高价值任务。但如果你是个**不懂定价的开发者**,图方便默认接了 pro 版的 endpoint,**一个月账单可能会让你当场报警**。
|
||||
|
||||
**怎么办**:
|
||||
- 在你的 API 客户端里**显式指定模型名**(`gpt-5.5` 而不是 `gpt-5.5-pro`)
|
||||
- 上预算告警(OpenAI 平台有)
|
||||
- 做 Agent/长任务时**默认不用 pro 版**,除非跑测试发现标准版解不了
|
||||
|
||||
### 坑 3:DeepSeek V4 的"preview 陷阱"
|
||||
|
||||
DeepSeek 官方给 V4 的定位是 **preview(预览版)**,不是 GA(正式版)。
|
||||
|
||||
preview 意味着什么?
|
||||
- ✅ 你能免费用、能下载权重、能自部署
|
||||
- ❌ 官方不保证 SLA
|
||||
- ❌ 随时可能调整权重、调整价格、调整 API 格式
|
||||
- ❌ 生产环境出问题,**找不到人负责**
|
||||
|
||||
国内很多自媒体吹"DeepSeek 又一次屠榜"的时候,**没告诉你这是 preview**。
|
||||
|
||||
**怎么办**:
|
||||
- 如果你做的是关键业务,**preview 只用来做验证、选型、培训**,不要直接上生产
|
||||
- 真要上生产,**建议搭配 Claude 4.7 或 GPT-5.5 做 fallback**
|
||||
- 等 GA 版出来(预计 1-3 个月内)再大规模切流
|
||||
|
||||
---
|
||||
|
||||
## 六、行业视角:这七天意味着什么?
|
||||
|
||||
把三家事件串起来,我看到的**三个深层变化**:
|
||||
|
||||
**第一,闭源模型的"价格霸权"正式破了。**
|
||||
|
||||
过去 OpenAI 能定 $30/M 输出,Anthropic 能定 $25/M 输出,因为他们是"唯一能干活的"。现在 DeepSeek V4 用 1/10 的价格干出 SWE-bench Verified 83.7% 的成绩,**证明了"便宜不等于差"**。下一轮 API 价格战不可避免。
|
||||
|
||||
**第二,MoE + 稀疏注意力 成了前沿模型的标配。**
|
||||
|
||||
DeepSeek V4 的 1.6T 总参数 / 49B 激活,和 DSA2 稀疏注意力,让"万亿参数 + 百万上下文"在单机上可行。OpenAI 和 Anthropic 没有公开他们的架构,但业内推测也在往这个方向走。**纯 Dense 模型时代在 2026 基本结束了**。
|
||||
|
||||
**第三,中美 AI 出现了"架构分叉"。**
|
||||
|
||||
美国(OpenAI/Anthropic)走的是**闭源 + 云服务 + 订阅制**路线;中国(DeepSeek/Qwen/Kimi)走的是**开源 + 国产算力 + 私有化**路线。这不是简单的"追赶",是两套生态的同时存在。未来 3-5 年,**全球 AI 格局会从"美国一家独大"变成"双轨并行"**。
|
||||
|
||||
---
|
||||
|
||||
## 最后:我的一句话建议
|
||||
|
||||
看完这篇你如果只记得一件事,就记这个:
|
||||
|
||||
> **开发者 + 创作者**:DeepSeek V4 打底,Claude 4.7 攻坚,GPT-5.5 作备选。
|
||||
>
|
||||
> **企业**:DeepSeek V4 私有化是未来 6 个月的重点试水方向,不上就晚了。
|
||||
|
||||
---
|
||||
|
||||
**利益披露**:这篇文章的初稿由我(老邓)和 Claude Opus 4.7 协作完成。涉及 Claude 的部分我刻意多挑了毛病(新 tokenizer 涨价、学习成本、价格没那么透明),目的是避免"AI 自吹 AI"的嫌疑。三家的官方数据全部交叉验证过,但 benchmark 口径不统一这事儿谁也解决不了——**最终以你自己业务场景的测试为准**。
|
||||
|
||||
---
|
||||
|
||||
**素材来源**:
|
||||
- [OpenAI - Introducing GPT-5.5](https://openai.com/index/introducing-gpt-5-5/)
|
||||
- [Anthropic - What's new in Claude Opus 4.7](https://platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7)
|
||||
- [CNBC - OpenAI announces GPT-5.5](https://www.cnbc.com/2026/04/23/openai-announces-latest-artificial-intelligence-model.html)
|
||||
- [CNBC - DeepSeek V4 preview release](https://www.cnbc.com/2026/04/24/deepseek-v4-llm-preview-open-source-ai-competition-china.html)
|
||||
- [腾讯云 - DeepSeek V4 API 完全指南](https://cloud.tencent.com/developer/article/2659300)
|
||||
- [SegmentFault - DeepSeek V4 正式上线](https://segmentfault.com/a/1190000047727828)
|
||||
- [华尔街见闻 - DeepSeek V4 预览版发布](https://awtmt.com/articles/3770782)
|
||||
- [HuggingFace - DeepSeek-V4-Pro](https://huggingface.co/deepseek-ai/DeepSeek-V4-Pro)
|
||||
|
||||
---
|
||||
|
||||
*写这文章花了我 6 小时——扒官方 blog、对 benchmark 口径、算价格实战账。如果对你有用,点赞/在看/转发三连,老邓下一篇继续唠。*
|
||||
BIN
articles/015/cover.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.7 MiB |
BIN
articles/015/decision.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 632 KiB |
BIN
articles/015/price.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 702 KiB |
@ -0,0 +1,433 @@
|
||||
# 还在手敲 Prompt?Claude Code 之父:我的工作就是写循环!Loop Engineering 保姆级指南
|
||||
|
||||
> 发布日期:2026-06-12
|
||||
> 分类:技术指南 / AI 工程
|
||||
> 作者:老邓唠AI
|
||||
|
||||
|
||||
|
||||
这几天技术圈被一个新词刷屏了:**Loop Engineering(循环工程)**。
|
||||
|
||||
起因是 6 月 7 日,开发者圈的老熟人 Peter Steinberger 在 X 上发了一句话:"你不应该再手动给编程智能体写提示词了,你应该设计循环,让循环去提示你的智能体。"第二天,Google 的工程大佬 Addy Osmani(写《JavaScript 设计模式》那位)直接跟了一篇长文,标题就叫《Loop Engineering》。更狠的是 Anthropic 的 Claude Code 负责人 Boris Cherny,他的原话是:
|
||||
|
||||
> "我已经不直接提示 Claude 了。我有一堆循环在跑,它们负责提示 Claude、决定接下来做什么。我的工作就是写循环。"
|
||||
|
||||
做出全世界最火 AI 编程工具的人,自己都不写 prompt 了。
|
||||
|
||||
我花了三个晚上,把 Addy Osmani 的原文和社区里能找到的资料都啃了一遍,又在自己的项目上实际跑了两个小循环,今天就用大白话和大家聊聊这个东西:它到底是什么、核心原理、六大要素,文章最后还有一个完整的实战案例,配置文件可以直接抄作业。
|
||||
|
||||
建议收藏,内容有点长。
|
||||
|
||||
## 什么是 Loop Engineering?
|
||||
|
||||
用大白话说:**以前是你坐在电脑前,一条一条给 AI 发指令;现在是你设计一个系统,这个系统自己给 AI 发指令,一直干到目标达成为止。**
|
||||
|
||||
打个比方,你招了个能力很强的实习生:
|
||||
|
||||
- 旧玩法:你坐他旁边,说一句他做一步。"改这个 bug",他改完你看一眼,"不对重来",他再来一遍。他干活的每一分钟你都得在场。
|
||||
- 新玩法:你给他定一套工作制度。每天早上自己去看 bug 列表,挑出能修的修掉,修完自己跑测试,测试过了交给质检员复核,复核过了提交,搞不定的放进"待人工处理"清单。然后你该干嘛干嘛,早上来只看结果。
|
||||
|
||||
这套"工作制度"就是循环(Loop),设计这套制度的活儿,就是循环工程。
|
||||
|
||||
熟悉项目管理的朋友会发现,这其实很像工程学里的 PDCA 循环(计划-执行-检查-处理),只不过转圈的从人变成了 AI。
|
||||
|
||||
它和传统模式的差异,我整理了一个表:
|
||||
|
||||
| | 传统提示模式 | 循环模式 |
|
||||
|---|---|---|
|
||||
| 工作方式 | 一问一答,人盯着 | 系统自动迭代,人看结果 |
|
||||
| 你的角色 | 提示词工程师 | 规则制定者 |
|
||||
| 反馈方式 | 你看完手动改提示 | 测试、lint 自动验证 |
|
||||
| 适合场景 | 短任务、问答 | 复杂、长时间、可验证的任务 |
|
||||
|
||||
这是一个挺根本的思维转变:我们的工作不再是写出完美的提示词,而是设计出完美的反馈系统。
|
||||
|
||||
## AI 编程的三次革命
|
||||
|
||||
短短三年,AI 编程已经换了三次玩法,我画了张演进图:
|
||||
|
||||
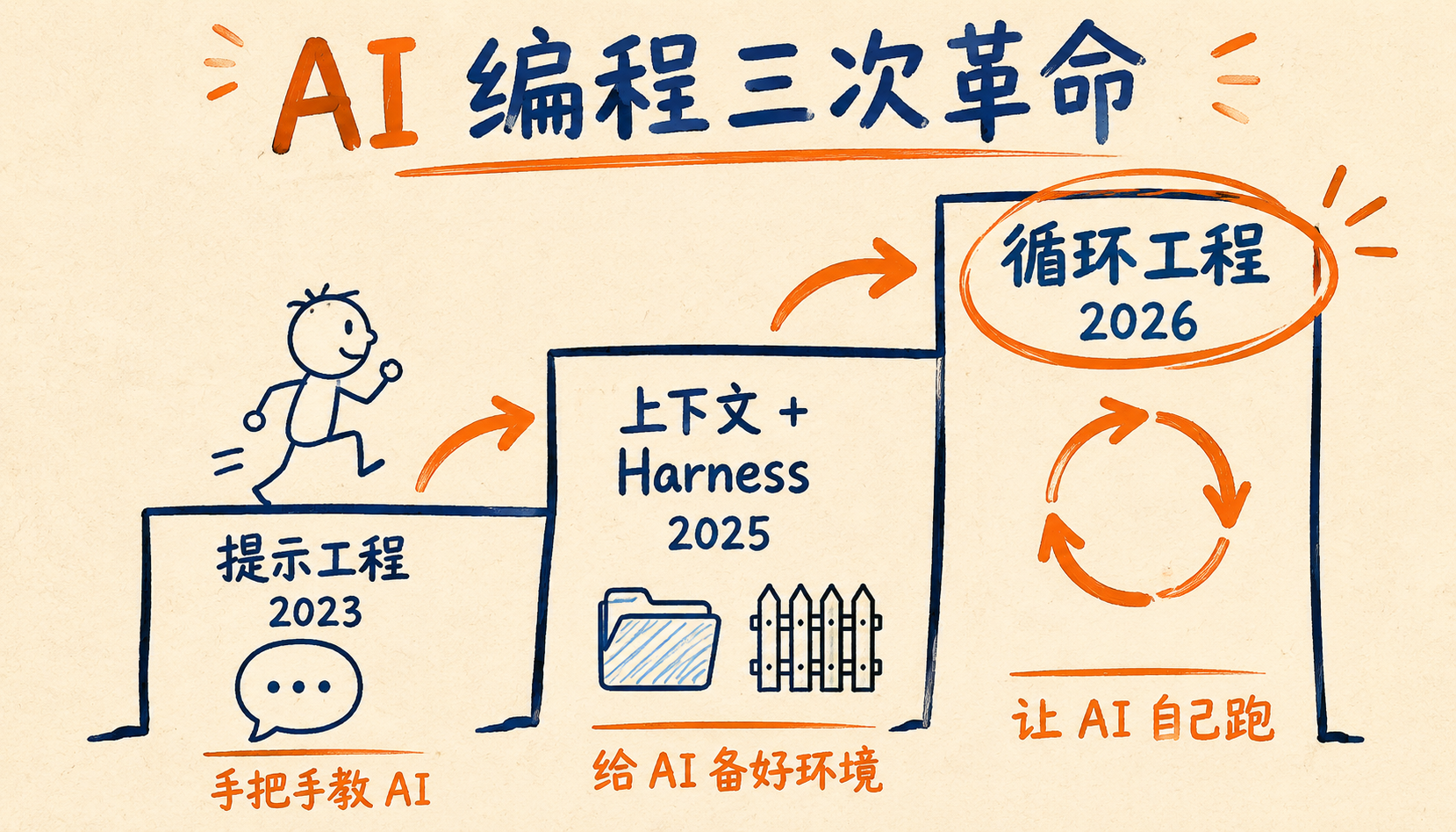
|
||||
|
||||
- **提示工程(2023)**:手把手教 AI。一句话问不好,答案就跑偏,所以那两年"提示词模板"满天飞。
|
||||
- **上下文工程 + Harness(2025)**:给 AI 备好环境。RAG、记忆管理、工具调用、沙箱权限,把 AI 圈在一个安全的环境里干活。我 4 月那篇讲 Harness 的文章(《2026 年最火的 Harness 到底是什么鬼》)说的就是这个阶段,没看过的朋友可以翻一下。
|
||||
- **循环工程(2026)**:让 AI 自己跑。人从"过程"里退出来,只管定目标和验收。
|
||||
|
||||
说实话,前两个阶段已经能解决大部分开发场景了。比如以前要手写的静态官网,现在提示词加上几个 skills,运营同学自己就能搞定;再比如一个后台管理系统,搭好一套成熟的上下文和 Harness,AI 一天能干完 80% 的活,剩下的就是人工测试优化。
|
||||
|
||||
Loop Engineering 要砍掉的,就是剩下那部分"人工盯着"的环节。
|
||||
|
||||
要注意的是,循环工程不是凭空冒出来的,它站在前面所有技术的肩膀上。我把这套体系总结成四层架构:
|
||||
|
||||
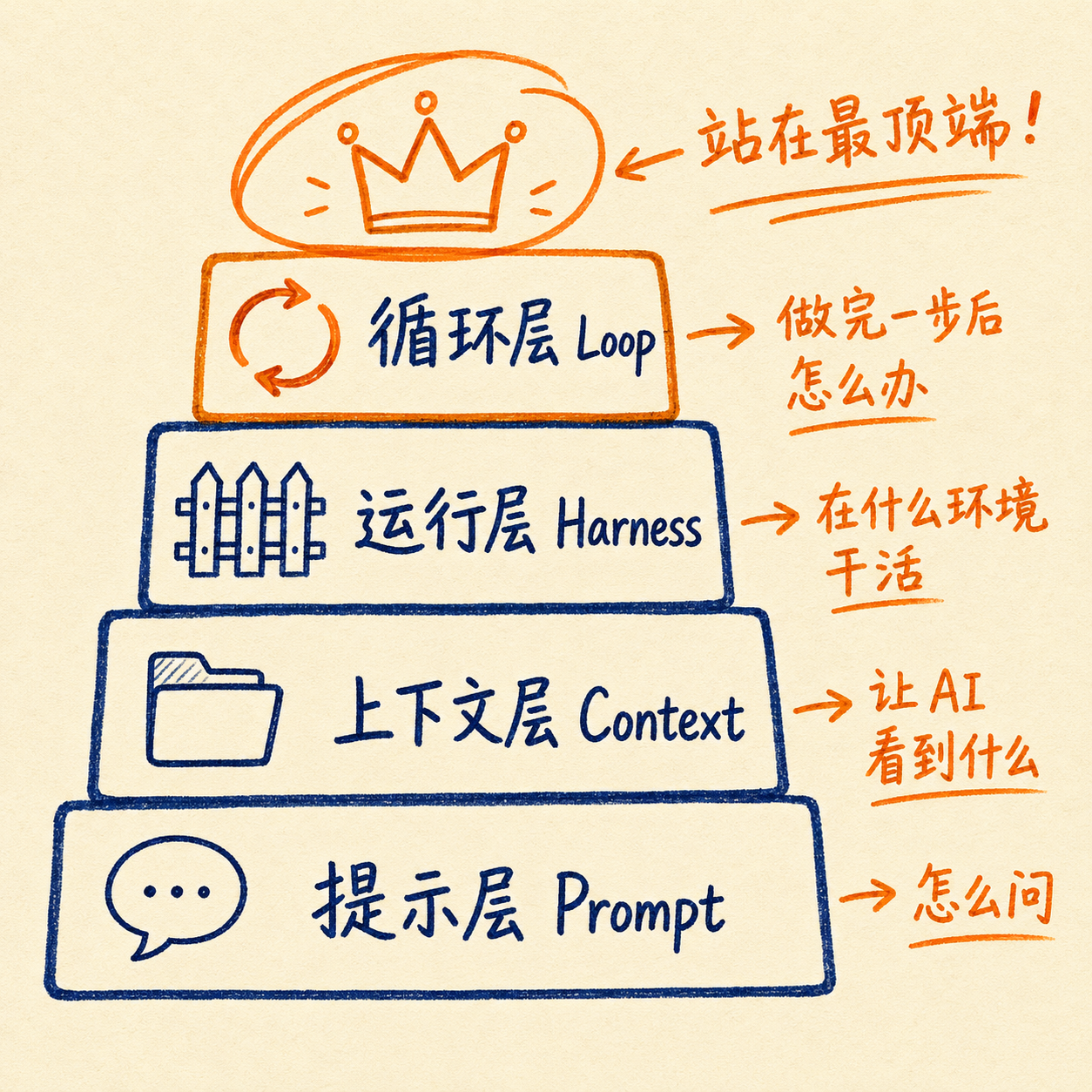
|
||||
|
||||
- **Prompt 层**解决"怎么问":角色设定、输出格式、示例
|
||||
- **Context 层**解决"让 AI 看到什么":RAG、记忆管理、文件检索
|
||||
- **Harness 层**解决"AI 在什么环境干活":工具调用、沙箱、权限控制
|
||||
- **Loop 层**解决"AI 做完一步后怎么办":自动检查、修正、继续还是停止
|
||||
|
||||
Loop 层站在最顶端,它关心的不是单次对话的质量,而是整个系统的自运行能力。所以别误会,循环工程不是说提示词没用了,提示词变成了循环里的一个零件。
|
||||
|
||||
下面开始上干货。
|
||||
|
||||
## 核心原理:五阶段循环
|
||||
|
||||
Addy Osmani 总结过一个通用模型:无论单 Agent 还是多 Agent,一个编码循环都遵循同样的五个阶段,一直转到满足"可验证的停止条件"为止。
|
||||
|
||||
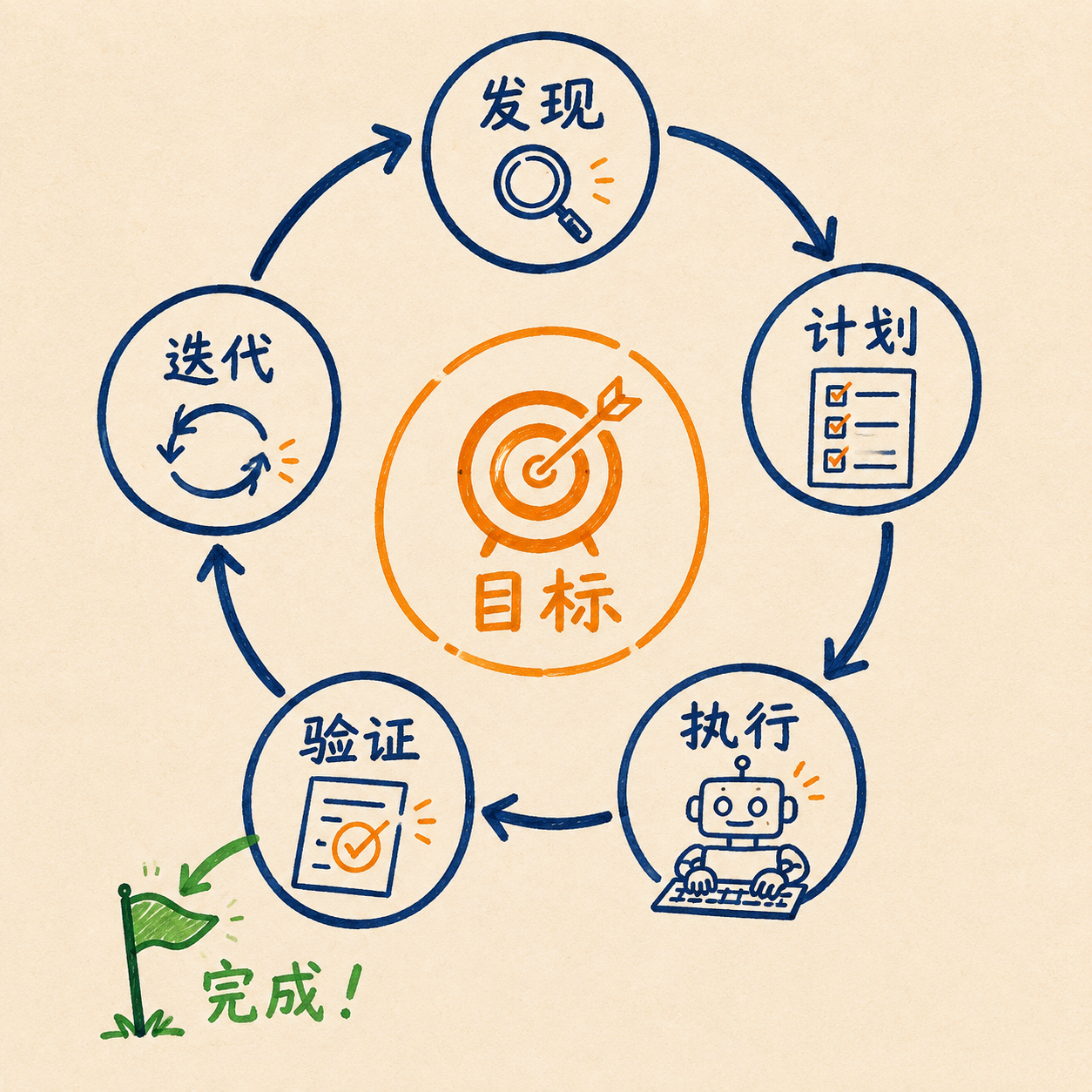
|
||||
|
||||
1. **发现(Discover)**:去哪找活儿?CI 失败日志、issue 列表、监控告警
|
||||
2. **计划(Plan)**:这个活儿怎么拆,先干哪个
|
||||
3. **执行(Execute)**:读代码、改文件、跑命令
|
||||
4. **验证(Verify)**:测试过没过?lint 干不干净?这一步必须是客观的,不能让 AI 自己说了算
|
||||
5. **迭代(Iterate)**:过了就推进下一项,没过就带着错误信息回到第 2 步重试
|
||||
|
||||
### 一个最核心的思想:状态存外面,别信上下文窗口
|
||||
|
||||
如果整篇文章只记一句话,记这句。
|
||||
|
||||
模型会遗忘,会漂移,上下文一压缩,你之前强调的约束可能就丢了。所以成熟的做法是:**所有状态都存在外部系统里**——git 仓库、markdown 文件、数据库、issue 系统都行。每次循环迭代都开一个全新的上下文窗口,从磁盘上读状态接着干。
|
||||
|
||||
这也是为什么社区里最早出圈的"土法循环"Ralph Loop 影响这么大,它就一行 bash:
|
||||
|
||||
```bash
|
||||
while :; do cat PROMPT.md | claude; done
|
||||
```
|
||||
|
||||
给大家拆解一下:每次循环都重新读 PROMPT.md 和当前代码库的状态,完全不要之前的对话历史。看着简单粗暴,但它恰好绕开了长对话上下文的所有毛病——忘事、漂移、越聊越乱。
|
||||
|
||||
(这玩法 2025 年就有人在用了,不过那会儿模型能力不够,跑一晚上基本是白烧钱,现在才算真正能打。)
|
||||
|
||||
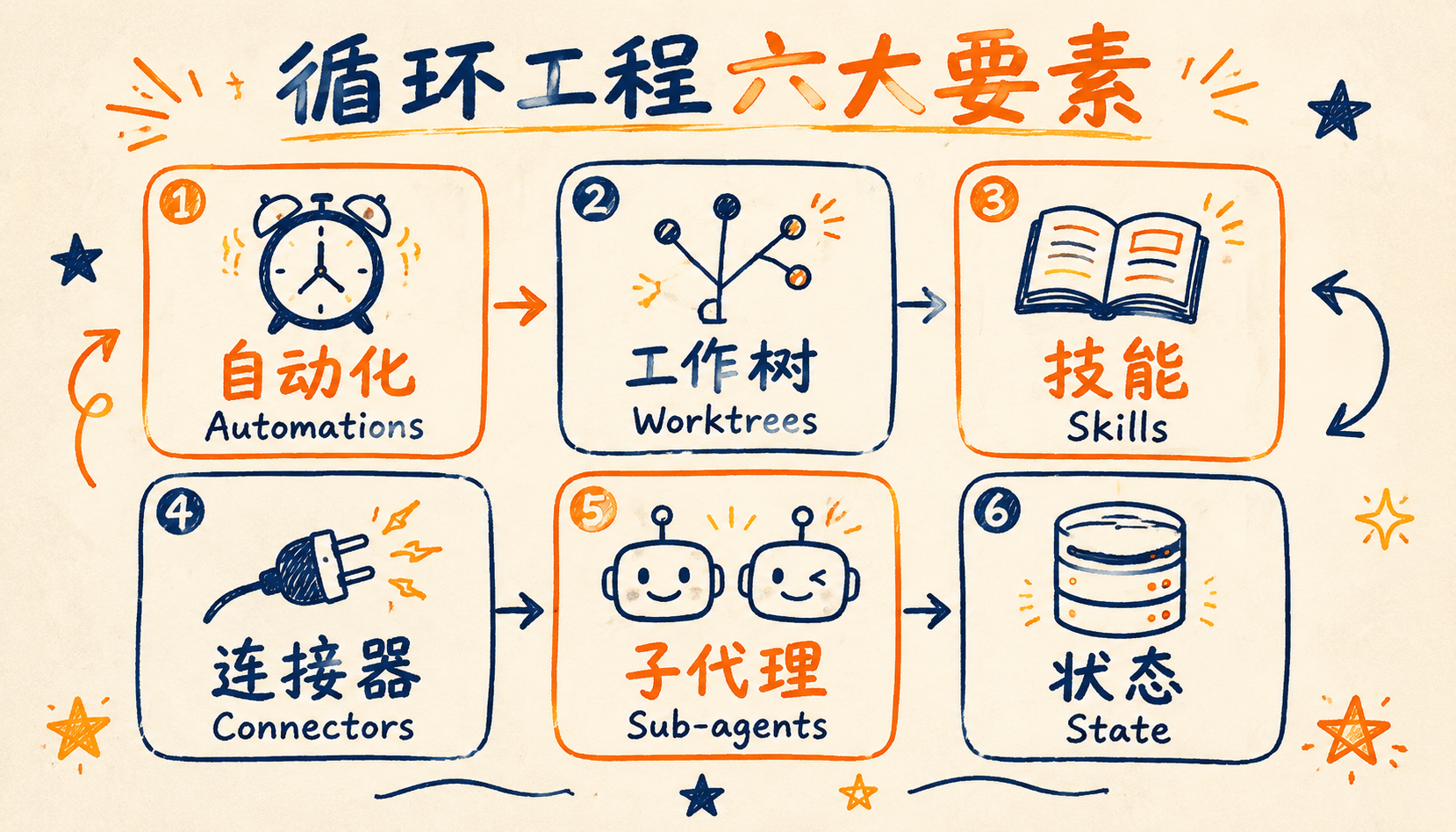
## 六大核心要素
|
||||
|
||||
Addy Osmani 指出,现在的主流 AI 编程工具(Claude Code、Codex 等)已经把循环工程需要的六大要素全部内置了,不用自己造轮子。理解了这六块积木,你在任何工具里都能搭出循环。
|
||||
|
||||
|
||||
|
||||
### 1. 自动化(Automations):让循环真正转起来
|
||||
|
||||
没有定时触发,"循环"就只是你手动跑了一次的脚本。自动化决定任务何时运行、多久跑一次。
|
||||
|
||||
几个典型场景:
|
||||
|
||||
- 每天早上 7 点半,自动处理前一天的 bug
|
||||
- 每当有新 PR 打开,自动跑一遍代码审查
|
||||
- 每两小时检查一次性能基准
|
||||
- 每周五下午自动生成 CHANGELOG
|
||||
|
||||
对应到 Claude Code,大概长这样:
|
||||
|
||||
```bash
|
||||
# 每天早上 6 点跑一次,分诊昨天的 CI 失败
|
||||
/loop "用 ci-triage 技能分析昨天的 CI 失败,给能修的开 PR" --schedule "0 6 * * *"
|
||||
|
||||
# 一直跑,直到条件为真才停
|
||||
/goal "test/auth 下所有测试通过,且 lint 零警告"
|
||||
```
|
||||
|
||||
`/goal` 有个很妙的设计:每轮结束后由一个独立的小模型来判断"做完了没有",写代码的不给自己打分。Codex 那边对应的是 Automations 标签页加分诊收件箱,原理一样。
|
||||
|
||||
### 2. 工作树(Worktrees):并行干活不打架
|
||||
|
||||
同时跑多个 AI,最大的问题是文件冲突——都改同一个目录,必然互相覆盖。Git worktree 给每个 Agent 一个独立的工作目录,共享仓库历史但不共享文件,各干各的,干完再合并。
|
||||
|
||||
```bash
|
||||
# 在独立工作树里开一个会话
|
||||
claude --worktree feature/add-search
|
||||
```
|
||||
|
||||
我个人理解,这就是把 git 那套多人协作机制,原封不动搬到了多 Agent 协作上。
|
||||
|
||||
### 3. 技能(Skills):经验的复用包
|
||||
|
||||
每开一个新会话,AI 就"失忆"一次,你总不能每次都把项目规范从头讲一遍。Skills 就是把项目知识固化到磁盘上:一个文件夹,里面放 SKILL.md、可选脚本和参考资料,AI 需要时自动调用。
|
||||
|
||||
它核心解决三个老毛病:
|
||||
|
||||
- 每次会话都要重新解释项目结构
|
||||
- AI 总忘记编码规范
|
||||
- 同一个错误在不同会话里反复出现
|
||||
|
||||
企业级的技能目录一般长这样:
|
||||
|
||||
```
|
||||
skills/
|
||||
database/
|
||||
SKILL.md
|
||||
scripts/
|
||||
migrate.sh
|
||||
references/
|
||||
schema.md
|
||||
api/
|
||||
SKILL.md
|
||||
testing/
|
||||
SKILL.md
|
||||
```
|
||||
|
||||
SKILL.md 写法很朴素,比如:
|
||||
|
||||
```markdown
|
||||
# 数据库技能
|
||||
## 我们怎么写数据库代码
|
||||
- 所有数据库操作走 Knex.js
|
||||
- 迁移文件统一放 migrations/ 目录
|
||||
- 每张表必须有 created_at 和 updated_at
|
||||
- 生产环境永远不要 DROP COLUMN
|
||||
## 怎么跑迁移
|
||||
npm run migrate
|
||||
```
|
||||
|
||||
注意一个细节:技能描述要写得**无聊而精确**。AI 靠这段描述决定什么时候调用它,写得太"聪明"反而容易误触发。
|
||||
|
||||
### 4. 连接器(Connectors):给循环装上手
|
||||
|
||||
连接器基于 MCP 协议,让循环能操作你已经在用的真实工具。它是"AI 告诉你该做什么"和"AI 实际帮你做完了"之间的关键区别。
|
||||
|
||||
常见的几类:
|
||||
|
||||
- Issue 跟踪:GitHub Issues、Linear、Jira
|
||||
- 通讯:Slack、飞书、钉钉
|
||||
- 数据库:PostgreSQL、MySQL、MongoDB
|
||||
- CI/CD:GitHub Actions、Jenkins、GitLab CI
|
||||
|
||||
没有连接器,循环只能在代码仓库里自嗨;有了它,循环才能开 PR、更新工单、给你发消息。
|
||||
|
||||
### 5. 子代理(Sub-agents):写代码的和验收的必须是两个人
|
||||
|
||||
这是质量的命门。让写代码的模型评判自己的代码,就像让学生给自己的考试打分,它一定手下留情。
|
||||
|
||||
所以最高效的循环设计原则是:一个代理负责实现,另一个代理负责验证。Claude Code 在 `.claude/agents/` 里定义,Codex 在 `.codex/agents/` 里用 TOML 定义。常见的分工是三层:一个探索、一个实现、一个审查。
|
||||
|
||||
代价是多烧点 token,但这个钱真不能省,后面实战部分给大家看具体配置。
|
||||
|
||||
### 6. 状态(State):循环的记忆保障
|
||||
|
||||
前面说了,模型会遗忘,但仓库不会。所有正经的循环都靠外部状态记住"干到哪了"。常见的存储方式:
|
||||
|
||||
- Markdown 文件:STATE.md、PROGRESS.md
|
||||
- 任务队列:tasks.json
|
||||
- Issue 系统:GitHub Issues、Linear
|
||||
- 数据库:SQLite
|
||||
|
||||
一个实际的 STATE.md 大概长这样:
|
||||
|
||||
```markdown
|
||||
# Loop State
|
||||
## 2026-06-11
|
||||
### 已完成
|
||||
- [x] 修复 #123:登录页 CSS 错位
|
||||
### 进行中
|
||||
- [ ] 修复 #124:API 返回 500
|
||||
- 尝试1:改 auth 中间件,测试没过
|
||||
- 尝试2:排查数据库连接,进行中
|
||||
### 待处理
|
||||
- [ ] auth 模块补单元测试
|
||||
```
|
||||
|
||||
下次循环启动,先读这个文件,就知道上次干到哪了,连失败的尝试都不会重复踩。
|
||||
|
||||
## 闭环 vs 开环:先分清你要哪种
|
||||
|
||||
循环有两种基本类型,适用场景完全不同:
|
||||
|
||||
| | 闭环 | 开环 |
|
||||
|---|---|---|
|
||||
| 目标 | 固定、可验证("测试全绿") | 开放、探索式("找出性能瓶颈") |
|
||||
| 停止条件 | 条件满足自动停 | 预算/迭代次数耗尽才停 |
|
||||
| 成本 | 可预估 | 容易失控 |
|
||||
| 适合谁 | 所有人,尤其新手 | 预算充足的老手 |
|
||||
|
||||
一个合格的闭环,五样东西缺一不可:
|
||||
|
||||
1. **明确的目标**:精确定义"完成"长什么样
|
||||
2. **充足的上下文**:VISION.md、ARCHITECTURE.md、RULES.md 这类文件备齐
|
||||
3. **受限的动作**:只给必要的工具,不多给一分权限
|
||||
4. **客观的反馈**:测试、lint、类型检查,机器说了算
|
||||
5. **清晰的停止条件**:可验证的成功标准,外加迭代上限兜底
|
||||
|
||||
我的建议是都从闭环开始。等你完全摸透了闭环,预算也扛得住了,再去碰开环。
|
||||
|
||||
## 实战:搭一个自动修复 CI 失败的循环
|
||||
|
||||
下面带大家完整走一遍,目标是:**每天早上自动跑一次,把前一天 CI 挂掉的问题能修的修掉、开好 PR,搞不定的留给人。**
|
||||
|
||||
整个循环跑起来是这样的:
|
||||
|
||||
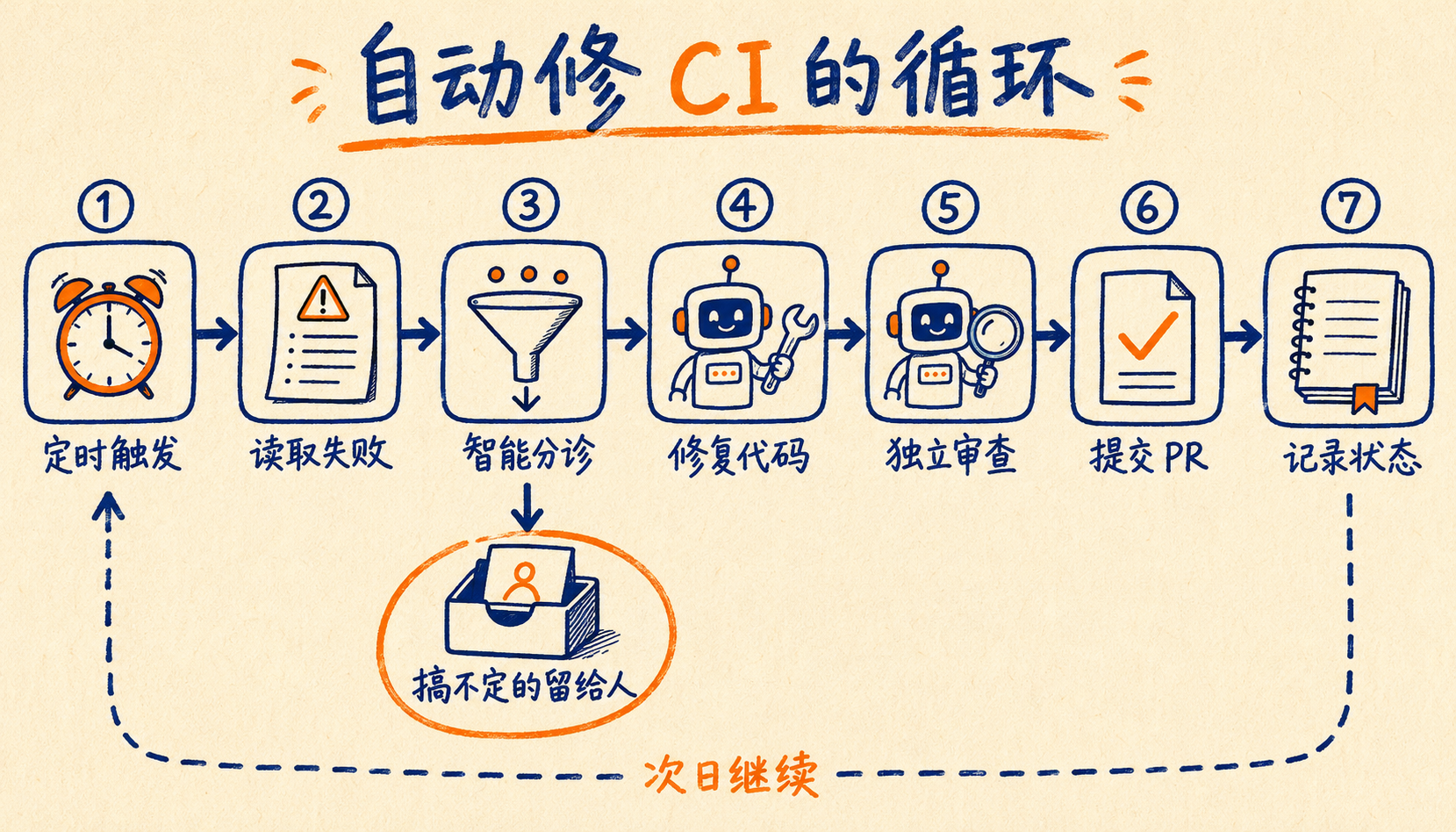
|
||||
|
||||
### 步骤 1:准备项目结构
|
||||
|
||||
```
|
||||
your-project/
|
||||
.claude/
|
||||
agents/
|
||||
ci-fixer.md
|
||||
code-reviewer.md
|
||||
skills/
|
||||
ci-triage/
|
||||
SKILL.md
|
||||
code-fixer/
|
||||
SKILL.md
|
||||
STATE.md
|
||||
.github/
|
||||
workflows/
|
||||
ci-fix-loop.yml
|
||||
```
|
||||
|
||||
### 步骤 2:写分诊技能
|
||||
|
||||
`skills/ci-triage/SKILL.md`:
|
||||
|
||||
```markdown
|
||||
# CI 分诊技能
|
||||
## 目的
|
||||
分析 CI 失败日志,定位根本原因,评估修复优先级。
|
||||
## 输入
|
||||
- CI 运行日志、失败的测试名和报错信息
|
||||
## 分类规则
|
||||
- 简单:语法错误、拼写错误、lint 警告
|
||||
- 中等:报错信息明确的测试失败、依赖版本冲突
|
||||
- 困难:间歇性失败、复杂逻辑错误、性能问题
|
||||
## 输出格式
|
||||
{
|
||||
"issue_type": "test_failure",
|
||||
"root_cause": "用户不存在时 user service 返回了 null",
|
||||
"difficulty": "medium",
|
||||
"auto_fixable": true,
|
||||
"file_path": "src/services/user.js"
|
||||
}
|
||||
```
|
||||
|
||||
### 步骤 3:写修复技能
|
||||
|
||||
`skills/code-fixer/SKILL.md`:
|
||||
|
||||
```markdown
|
||||
# 代码修复技能
|
||||
## 修复原则
|
||||
1. 只修和 CI 失败直接相关的问题
|
||||
2. 不顺手重构不相关的代码
|
||||
3. 代码风格跟现有代码保持一致
|
||||
4. 修完必须通过 lint 和类型检查
|
||||
## 输出
|
||||
- 修改后的文件、修复说明、测试运行结果
|
||||
```
|
||||
|
||||
第 2 条特别重要。不写这条,AI 修一个 bug 能顺手给你"优化"二十个文件,review 的人直接崩溃。
|
||||
|
||||
### 步骤 4:配置子代理
|
||||
|
||||
干活的 `.claude/agents/ci-fixer.md`:
|
||||
|
||||
```markdown
|
||||
---
|
||||
name: ci-fixer
|
||||
description: 修复 CI 失败
|
||||
tools: Edit, Bash, Read
|
||||
---
|
||||
用 code-fixer 技能修复指定的 CI 问题。
|
||||
改完必须跑测试,测试通过才能开 PR。
|
||||
```
|
||||
|
||||
验收的 `.claude/agents/code-reviewer.md`:
|
||||
|
||||
```markdown
|
||||
---
|
||||
name: code-reviewer
|
||||
description: 审查代码变更
|
||||
tools: Read, Grep, Bash
|
||||
---
|
||||
审查代码变更的正确性、安全性和代码风格。
|
||||
对照 skills 里的项目规范逐条检查,给出通过或退回的明确结论。
|
||||
```
|
||||
|
||||
注意两点:干活的没有审查权,审查的没有改代码权;审查代理可以配更强的模型——干活用便宜的,把关用贵的,这是省钱和质量兼顾的常见搭配。
|
||||
|
||||
### 步骤 5:用 GitHub Actions 定时触发
|
||||
|
||||
`.github/workflows/ci-fix-loop.yml`(核心部分):
|
||||
|
||||
```yaml
|
||||
name: CI Fix Loop
|
||||
on:
|
||||
schedule:
|
||||
- cron: '0 6 * * *' # 每天早上 6 点
|
||||
workflow_dispatch: # 也允许手动触发
|
||||
jobs:
|
||||
fix-ci:
|
||||
runs-on: ubuntu-latest
|
||||
steps:
|
||||
- uses: actions/checkout@v4
|
||||
- run: npm ci
|
||||
- run: npm install -g @anthropic-ai/claude-code
|
||||
- name: Run CI fix loop
|
||||
env:
|
||||
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
|
||||
run: |
|
||||
claude -p "
|
||||
用 ci-triage 技能分析昨天所有失败的 CI 运行。
|
||||
对每个 auto_fixable 的问题:
|
||||
1. 开独立分支
|
||||
2. 派 ci-fixer 子代理修复
|
||||
3. 派 code-reviewer 子代理审查
|
||||
4. 审查通过才开 PR
|
||||
5. 全部结果写入 STATE.md
|
||||
搞不定的问题,在 STATE.md 里标记为待人工处理。
|
||||
" --max-turns 50
|
||||
- name: Commit state
|
||||
run: |
|
||||
git add STATE.md
|
||||
git commit -m "update loop state" || true
|
||||
git push
|
||||
```
|
||||
|
||||
### 步骤 6:初始化状态文件
|
||||
|
||||
`STATE.md`:
|
||||
|
||||
```markdown
|
||||
# CI Fix Loop State
|
||||
## 运行历史
|
||||
### 2026-06-11
|
||||
- 发现 3 个 CI 失败
|
||||
- 自动修复 2 个,开了 PR #125、#126
|
||||
- 1 个间歇性失败,标记待人工处理
|
||||
## 待处理
|
||||
- [ ] #127 间歇性测试失败,需要人看
|
||||
```
|
||||
|
||||
这一步看着简单,但它就是整个循环的"记忆",千万别省。
|
||||
|
||||
到这就齐活了。第二天早上你打开 GitHub,看到的是几个已经过完独立审查的 PR 在等你拍板,外加一份"哪些事需要人处理"的清单。
|
||||
|
||||
## 成本与安全:丑话说在前面
|
||||
|
||||
循环很强,但用不好,账单和事故都会找上门。这部分是我自己实践下来最想提醒大家的。
|
||||
|
||||
**先说钱。** 循环烧 API 额度的速度远超手动模式,在一个中等规模代码库上跑 50-100 次迭代,花掉几百到上千块很正常。几条管控经验:
|
||||
|
||||
1. **永远不要省略最大迭代数**。没有 max-iterations 的循环就是一张空白支票
|
||||
2. **从 10-20 次迭代的小规模开始**,观察几天行为再扩大
|
||||
3. **算 ROI**:花 500 块的循环帮你省 20 小时,值;替你干一个 30 分钟的活,不值
|
||||
4. **便宜模型干粗活,贵模型把关**:分诊、修复用 Sonnet 级别就够,审查再上强模型
|
||||
5. **设置每日用量警报**,避免早上醒来看到惊喜账单
|
||||
|
||||
**再说安全。** 几条底线:
|
||||
|
||||
1. 第一个循环从**只读任务**开始——只分析、只写报告,不改代码不合并,最坏的结果也就是一份没用的报告
|
||||
2. 工具权限用白名单,删库、改生产配置这类操作永远不进白名单
|
||||
3. **循环产出的代码,合并前必须有人看**。验收代理给的"通过"是一个声明,不是证明
|
||||
4. 每一轮干了什么都留日志,出问题能查
|
||||
|
||||
最后还有一个比账单更隐蔽的坑:循环交付代码的速度,可能远超你理解代码的速度。哪天你发现仓库里大片代码自己既没写过也没真正读懂过,那就是该踩刹车的信号。Addy Osmani 原文里有句话我印象很深,送给大家:
|
||||
|
||||
> 像一个打算继续当工程师的人那样构建循环,而不是像一个只负责按启动键的人。
|
||||
|
||||
## 最后唠几句
|
||||
|
||||
三年时间,我们从"怎么问 AI"卷到"怎么让 AI 自己干",变化确实快。但循环工程的门槛其实不在技术——配置文件上面都给你了——而在于你愿不愿意把一件模糊的活儿想清楚:什么算完成?哪些动作允许?失败了怎么办?什么时候必须停?
|
||||
|
||||
这四个问题答得越清楚,你的循环就越靠谱。反过来说,连人都说不清的目标,AI 转一万圈也转不出来。
|
||||
|
||||
建议今天就动手:挑一件无聊但天天要干的事(CI 分诊就很合适),搭一个只读的闭环,跑一个礼拜看看。等你看到第一份循环自动生成的报告时,你就明白 Boris Cherny 那句"我的工作就是写循环"是什么感觉了。
|
||||
|
||||
我是老邓,咱们下篇见。
|
||||
BIN
articles/016/ci-loop-flow.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.4 MiB |
BIN
articles/016/cover.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.4 MiB |
BIN
articles/016/evolution.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.2 MiB |
BIN
articles/016/five-stages.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.3 MiB |
BIN
articles/016/four-layers.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.5 MiB |
BIN
articles/016/six-elements.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 2.1 MiB |
294
doc/passport/image2图片生成.md
Normal file
@ -0,0 +1,294 @@
|
||||
# WhatAI 图像生成技能(curl/bash)
|
||||
|
||||
通过 WhatAI 的 OpenAI 兼容接口,调用 `gpt-image-2` 模型:
|
||||
|
||||
- **文生图**:`/v1/images/generations` —— 纯文字描述生成新图
|
||||
- **图像编辑 / 图生图**:`/v1/images/edits` —— 引用一张或多张已有图片再调整(换背景、改风格、多图合成、局部重绘)
|
||||
|
||||
## 关键配置
|
||||
|
||||
| 项 | 值 |
|
||||
|----|----|
|
||||
| Base URL | `https://api.whatai.cc` |
|
||||
| 文生图路径 | `/v1/images/generations` |
|
||||
| 图像编辑路径 | `/v1/images/edits` |
|
||||
| 模型 | `gpt-image-2` |
|
||||
| 协议 | 完全兼容 OpenAI 官方接口 |
|
||||
|
||||
> 密钥已通过数字员工密钥库自动注入到本技能中,**直接执行 curl 即可**,不要再 `export`。
|
||||
> 下面所有 `Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge` 在你看到这段文字时,已被替换为真实 key。
|
||||
|
||||
---
|
||||
|
||||
## 触发场景
|
||||
|
||||
当用户提出以下任一类请求时,使用本技能:
|
||||
|
||||
**文生图(用 `/v1/images/generations`)**
|
||||
|
||||
1. 直接生成图像:"帮我画一只赛博朋克风格的猫"、"生成一张产品海报"
|
||||
2. 把 `dall-e-3` / `gpt-image-1` 换成 `gpt-image-2`
|
||||
|
||||
**图像编辑 / 图生图(用 `/v1/images/edits`)**
|
||||
|
||||
3. 引用某张图调整:"把这张照片背景换成海滩"、"把这张图改成吉卜力风格"
|
||||
4. 多图合成:"让图一的人物拿着图二的产品"
|
||||
5. 局部重绘:"只把图里的沙发换成绿色,其它不动"
|
||||
|
||||
---
|
||||
|
||||
## 标准用法
|
||||
|
||||
### 方式 1:最简调用
|
||||
|
||||
```bash
|
||||
curl https://api.whatai.cc/v1/images/generations \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-image-2",
|
||||
"prompt": "a cyberpunk fox sitting on a neon-lit rooftop in tokyo at night, cinematic lighting, ultra detailed, 8k",
|
||||
"size": "1024x1024",
|
||||
"n": 1
|
||||
}'
|
||||
```
|
||||
|
||||
### 方式 2:调用 + 自动下载到工作目录(推荐)
|
||||
|
||||
```bash
|
||||
URL=$(curl -sS https://api.whatai.cc/v1/images/generations \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-image-2",
|
||||
"prompt": "a serene japanese garden at dawn, watercolor style",
|
||||
"size": "1024x1024",
|
||||
"n": 1
|
||||
}' | jq -r '.data[0].url')
|
||||
|
||||
curl -sS -o output.png "$URL"
|
||||
echo "✅ 已保存到 output.png"
|
||||
echo "🔗 原始 URL: $URL"
|
||||
```
|
||||
|
||||
### 方式 3:批量生成
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/generations \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-image-2",
|
||||
"prompt": "a cute corgi astronaut floating in space",
|
||||
"size": "1024x1024",
|
||||
"n": 4
|
||||
}' \
|
||||
| jq -r '.data[].url' \
|
||||
| awk '{print "curl -sS -o img_" NR ".png \"" $0 "\""}' \
|
||||
| bash
|
||||
```
|
||||
|
||||
### 方式 4:只拿 URL 不下载
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/generations \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-image-2",
|
||||
"prompt": "minimalist mountain logo, flat design",
|
||||
"size": "1024x1024",
|
||||
"n": 1
|
||||
}' \
|
||||
| jq -r '.data[0].url'
|
||||
```
|
||||
|
||||
### 方式 5:查看模型对 prompt 的改写(调试用)
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/generations \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-H "Content-Type: application/json" \
|
||||
-d '{
|
||||
"model": "gpt-image-2",
|
||||
"prompt": "武则天",
|
||||
"size": "1024x1024",
|
||||
"n": 1
|
||||
}' \
|
||||
| jq '{revised_prompt: .data[0].revised_prompt, url: .data[0].url, usage}'
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 图像编辑 / 图生图(引用已有图片调整)
|
||||
|
||||
用 `/v1/images/edits` 接口。与文生图最大的区别:**请求体是 `multipart/form-data` 表单,不是 JSON**。
|
||||
|
||||
> ⚠️ 用 `-F` 提交时**不要**再手动加 `-H "Content-Type: application/json"`。
|
||||
> curl 会自动设置 `multipart/form-data` 并带上 boundary,手动加 JSON 头会直接 400。
|
||||
|
||||
> 兼容性说明:WhatAI 宣称完全兼容 OpenAI 官方接口,以下 curl 按 OpenAI 官方
|
||||
> `images/edits` 规范编写。首次使用请实测一次,确认字段名(`image` / `image[]`)
|
||||
> 和返回格式(`url` / `b64_json`)。
|
||||
|
||||
### 与文生图的接口差异
|
||||
|
||||
| 项 | 文生图 generations | 图像编辑 edits |
|
||||
|----|----|----|
|
||||
| 路径 | `/v1/images/generations` | `/v1/images/edits` |
|
||||
| 提交方式 | `-d '{...}'`(JSON) | `-F "k=v"`(表单) |
|
||||
| 必填 | `prompt` | `image` + `prompt` |
|
||||
| 参考图 | 不支持 | `image`(可传多张) |
|
||||
| 局部重绘 | 不支持 | `mask`(可选蒙版) |
|
||||
|
||||
### 方式 A:整图调整(引用一张图 → 改)
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/edits \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-F "model=gpt-image-2" \
|
||||
-F "image=@input.png" \
|
||||
-F "prompt=把背景换成日落海滩,人物姿势和服装保持不变" \
|
||||
-F "size=1024x1024" \
|
||||
-F "n=1"
|
||||
```
|
||||
|
||||
### 方式 B:多图参考 / 合成
|
||||
|
||||
传多张参考图,prompt 里用"图一""图二"指代:
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/edits \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-F "model=gpt-image-2" \
|
||||
-F "image[]=@person.png" \
|
||||
-F "image[]=@product.png" \
|
||||
-F "prompt=让图一的人物手里拿着图二的产品,自然合影"
|
||||
```
|
||||
|
||||
> 多图字段名按 OpenAI 官方规范是 `image[]`(重复传)。若 WhatAI 报字段错误,
|
||||
> 改成重复的 `-F "image=@a.png" -F "image=@b.png"` 再试。
|
||||
|
||||
### 方式 C:局部重绘(mask 蒙版)
|
||||
|
||||
`mask` 是一张和原图**同尺寸**的 PNG:透明区域(alpha=0)= 要重新生成的部分,
|
||||
不透明区域保持不变。
|
||||
|
||||
```bash
|
||||
curl -sS https://api.whatai.cc/v1/images/edits \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-F "model=gpt-image-2" \
|
||||
-F "image=@room.png" \
|
||||
-F "mask=@room-mask.png" \
|
||||
-F "prompt=把沙发换成一张绿色天鹅绒沙发"
|
||||
```
|
||||
|
||||
### 方式 D:编辑 + 自动下载(推荐,兼容 url / b64_json 两种返回)
|
||||
|
||||
edits 接口的返回字段可能是 `url`,也可能是 `b64_json`(base64),下面脚本两种都兼容:
|
||||
|
||||
```bash
|
||||
RESP=$(curl -sS https://api.whatai.cc/v1/images/edits \
|
||||
-H "Authorization: Bearer sk-8NXnGENP8fySh2a8L4xkvJX59yXVIKVqvPnlRUsBVo6jiFge" \
|
||||
-F "model=gpt-image-2" \
|
||||
-F "image=@input.png" \
|
||||
-F "prompt=把这张图改成吉卜力动画风格" \
|
||||
--max-time 180)
|
||||
|
||||
# 优先取 url,没有就把 b64_json 解码成 png
|
||||
URL=$(echo "$RESP" | jq -r '.data[0].url // empty')
|
||||
if [ -n "$URL" ]; then
|
||||
curl -sS -o output.png "$URL"
|
||||
echo "🔗 原始 URL: $URL"
|
||||
else
|
||||
echo "$RESP" | jq -r '.data[0].b64_json' | base64 -d > output.png
|
||||
fi
|
||||
echo "✅ 已保存到 output.png"
|
||||
```
|
||||
|
||||
### 输入图片要求
|
||||
|
||||
- 格式:PNG / JPEG / WebP
|
||||
- 大小:单张建议 < 25MB
|
||||
- `mask` 必须是 PNG,且尺寸与 `image` 完全一致
|
||||
- 路径前的 `@` 不能漏:`-F "image=@input.png"`,`@` 表示读取本地文件内容
|
||||
|
||||
---
|
||||
|
||||
## 响应结构
|
||||
|
||||
```json
|
||||
{
|
||||
"created": 1777361358,
|
||||
"data": [
|
||||
{
|
||||
"revised_prompt": "模型自动优化后的 prompt 版本",
|
||||
"url": "https://webstatic.aiproxy.vip/output/.../xxx.png"
|
||||
}
|
||||
],
|
||||
"model": "gpt-image-2",
|
||||
"usage": {
|
||||
"total_tokens": 1016,
|
||||
"input_tokens": 456,
|
||||
"output_tokens": 560
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
关键字段:
|
||||
- `data[].url` — 图片地址(**临时链接**,建议立刻下载保存)
|
||||
- `data[].revised_prompt` — 模型对原 prompt 的改写(调试时很有用)
|
||||
- `usage` — token 消耗统计
|
||||
|
||||
---
|
||||
|
||||
## 常用参数
|
||||
|
||||
| 参数 | 类型 | 说明 |
|
||||
|------|------|------|
|
||||
| `model` | string | 固定填 `gpt-image-2` |
|
||||
| `prompt` | string | 图像描述,越具体效果越好(建议英文或中英混合) |
|
||||
| `size` | string | `1024x1024`(方)/ `1024x1792`(竖)/ `1792x1024`(横) |
|
||||
| `n` | int | 一次生成几张,默认 1 |
|
||||
| `quality` | string | `standard` 或 `hd`(部分接口支持) |
|
||||
|
||||
> 图像编辑接口(`/v1/images/edits`)参数同上,但全部通过 `-F` 表单字段提交(不是 JSON);并额外支持 `image`(必填,参考图,可多张)和 `mask`(可选,局部重绘蒙版)。
|
||||
|
||||
---
|
||||
|
||||
## Prompt 写作建议(提升出图质量)
|
||||
|
||||
一个好的 prompt 通常包含 4 个要素:
|
||||
|
||||
1. **主体**:画什么(猫、城市、人物)
|
||||
2. **风格**:油画 / 写实 / 赛博朋克 / 吉卜力 / 像素风
|
||||
3. **细节**:颜色、材质、光照、角度
|
||||
4. **画质**:`highly detailed`, `8k`, `cinematic lighting`, `sharp focus`
|
||||
|
||||
示例对比:
|
||||
- ✅ 好:`a cyberpunk fox sitting on a neon-lit rooftop in tokyo at night, rain reflections, cinematic lighting, ultra detailed, 8k`
|
||||
- ❌ 差:`一只狐狸`
|
||||
|
||||
---
|
||||
|
||||
## 错误排查
|
||||
|
||||
| 现象 | 可能原因 | 处理 |
|
||||
|------|----------|------|
|
||||
| `401 Unauthorized` | 密钥库里 `WHATAI_API_KEY` 没建或值错 | 去数字员工密钥管理页新建/修正 |
|
||||
| `404 Not Found` | URL 漏了 `/v1` | 用 `https://api.whatai.cc/v1/images/generations` |
|
||||
| `model not found` | 模型名拼错 | 必须是 `gpt-image-2`(中划线) |
|
||||
| `jq: command not found` | 系统没装 jq | 工作站镜像里默认应该带;缺失时用 `apt install jq` |
|
||||
| 下载的 png 是 0 字节 | url 已过期 / 网络问题 | url 有时效,立即下载;加 `--retry 3` |
|
||||
| 请求超时 | 图像生成耗时较长 | 加 `--max-time 180` |
|
||||
| edits 接口 400 / JSON 解析错 | 用 `-F` 时手动加了 `-H "Content-Type: application/json"` | 删掉那行 `-H`,让 curl 自动设 multipart 边界 |
|
||||
| `No such file or directory` | `-F "image=@xxx"` 路径错或漏了 `@` | 确认文件存在;`@` 表示读取本地文件,不能省 |
|
||||
| edits 报 `mask` 尺寸不符 | 蒙版与原图尺寸不一致 | `mask` 必须是与 `image` 同尺寸的 PNG |
|
||||
|
||||
---
|
||||
|
||||
## 输出建议
|
||||
|
||||
- 默认把图片保存到当前任务工作目录下,文件名用语义化英文(如 `cyberpunk-fox.png`)
|
||||
- 把本地路径和原始 url 都告诉用户
|
||||
- 用户只要命令不要执行时,给完整 curl 即可
|
||||
@ -1,940 +0,0 @@
|
||||
# OpenClaw 源码架构深度分析
|
||||
|
||||
> 分析日期:2026-03-11
|
||||
> 源码版本:基于 GitHub 最新主分支
|
||||
> 分析工具:Claude Opus 4.6
|
||||
> 代码规模:约 43 万行 TypeScript,monorepo 架构
|
||||
|
||||
---
|
||||
|
||||
## 一、项目总览
|
||||
|
||||
OpenClaw 是一个**多通道 AI 智能体网关系统**——它不是一个简单的聊天机器人框架,而是一个完整的「AI 员工」运行时平台。其核心能力是:让大语言模型通过多种消息渠道(Slack、Telegram、Discord、WhatsApp 等 30+ 平台)接收指令、自主执行任务、并将结果回传。
|
||||
|
||||
### 1.1 Monorepo 结构
|
||||
|
||||
```
|
||||
openclaw/
|
||||
├── src/ # 核心运行时源码(主体)
|
||||
│ ├── gateway/ # WebSocket 网关服务器
|
||||
│ ├── acp/ # Agent Client Protocol 协议层
|
||||
│ ├── agents/ # Agent 运行时、模型集成、工具系统
|
||||
│ ├── memory/ # 向量检索 + 全文搜索记忆系统
|
||||
│ ├── plugins/ # 插件加载、注册、Hook 执行
|
||||
│ ├── channels/ # 通道管理器
|
||||
│ ├── routing/ # 消息路由与会话键解析
|
||||
│ ├── auto-reply/ # 心跳机制与自动回复
|
||||
│ ├── config/ # 配置加载与会话持久化
|
||||
│ ├── security/ # 安全审计与策略执行
|
||||
│ ├── infra/ # 基础设施(设备身份、TLS、投递)
|
||||
│ ├── cli/ # CLI 命令行界面
|
||||
│ ├── web/ # Web/WhatsApp Webhook 处理
|
||||
│ ├── terminal/ # 终端 TUI 组件
|
||||
│ └── media-understanding/# 多媒体理解(图片/音频)
|
||||
├── extensions/ # 34 个通道/功能插件
|
||||
├── packages/ # 兼容包(clawdbot、moltbot 旧名)
|
||||
├── apps/ # 原生客户端(macOS/iOS/Android)
|
||||
├── ui/ # React Web 管理界面
|
||||
├── skills/ # 内置技能
|
||||
├── docs/ # 文档
|
||||
├── test/ # 测试套件
|
||||
└── vendor/ # 第三方依赖(a2ui 等)
|
||||
```
|
||||
|
||||
### 1.2 技术栈
|
||||
|
||||
| 层面 | 技术选型 |
|
||||
|------|---------|
|
||||
| 语言 | TypeScript (ESM),Node.js 22+ |
|
||||
| 构建 | tsdown (基于 Rolldown) + Vite (UI) |
|
||||
| 包管理 | pnpm workspace (monorepo) |
|
||||
| 协议 | WebSocket + ACP (Agent Client Protocol) |
|
||||
| 存储 | SQLite (sqlite-vec + FTS5) + JSON 文件 |
|
||||
| 验证 | AJV Schema Validation |
|
||||
| 测试 | Vitest + V8 Coverage |
|
||||
| 容器 | Docker / Podman 多阶段构建 |
|
||||
| 桌面 | SwiftUI (macOS) / React Native (移动端) |
|
||||
|
||||
---
|
||||
|
||||
## 二、核心架构全景
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "外部消息平台"
|
||||
TG[Telegram]
|
||||
SL[Slack]
|
||||
DC[Discord]
|
||||
WA[WhatsApp]
|
||||
SG[Signal]
|
||||
FS[飞书]
|
||||
MORE[30+ 其他平台...]
|
||||
end
|
||||
|
||||
subgraph "OpenClaw 核心运行时"
|
||||
subgraph "Gateway 网关层"
|
||||
WS[WebSocket Server<br/>端口 18789]
|
||||
AUTH[认证中间件<br/>Ed25519 设备身份]
|
||||
PROTO[协议处理器<br/>AJV Schema 校验]
|
||||
RL[速率限制]
|
||||
end
|
||||
|
||||
subgraph "通道管理"
|
||||
CM[Channel Manager]
|
||||
CP1[Telegram Plugin]
|
||||
CP2[Slack Plugin]
|
||||
CP3[Discord Plugin]
|
||||
CPN[... N 个通道插件]
|
||||
end
|
||||
|
||||
subgraph "路由层"
|
||||
RT[Route Resolver<br/>消息 → Agent 映射]
|
||||
SK[Session Key Parser<br/>会话键解析]
|
||||
end
|
||||
|
||||
subgraph "ACP 协议层"
|
||||
ACP_SVR[ACP Server]
|
||||
ACP_TR[ACP Translator<br/>协议翻译器]
|
||||
ACP_SM[ACP Session Manager<br/>会话管理器 + Actor 队列]
|
||||
end
|
||||
|
||||
subgraph "Agent 运行时"
|
||||
PI[Pi Agent Runner<br/>LLM 推理引擎]
|
||||
TC[Tool Catalog<br/>工具注册表]
|
||||
SKL[Skills System<br/>技能加载器]
|
||||
SA[Subagent Registry<br/>子 Agent 注册]
|
||||
AP[Auth Profiles<br/>模型凭证管理]
|
||||
end
|
||||
|
||||
subgraph "记忆系统"
|
||||
MM[Memory Index Manager]
|
||||
VEC[向量检索<br/>sqlite-vec]
|
||||
FTS[全文搜索<br/>SQLite FTS5]
|
||||
EMB[Embedding Providers<br/>OpenAI/Gemini/Voyage/Ollama]
|
||||
end
|
||||
|
||||
subgraph "心跳系统"
|
||||
HB[Heartbeat Runner<br/>定时唤醒]
|
||||
HMD[HEARTBEAT.md<br/>任务配置文件]
|
||||
end
|
||||
|
||||
subgraph "存储层"
|
||||
SS[Session Store<br/>JSON/JSONL 文件]
|
||||
CF[Config Store<br/>config.json]
|
||||
DI[Device Identity<br/>密钥对存储]
|
||||
end
|
||||
end
|
||||
|
||||
subgraph "LLM 提供商"
|
||||
CLAUDE[Claude / Anthropic]
|
||||
GPT[GPT / OpenAI]
|
||||
GEM[Gemini / Google]
|
||||
QWEN[Qwen / 通义]
|
||||
OL[Ollama 本地模型]
|
||||
MORE_LLM[Grok/Groq/Azure/...]
|
||||
end
|
||||
|
||||
TG & SL & DC & WA & SG & FS & MORE --> CM
|
||||
CM --> CP1 & CP2 & CP3 & CPN
|
||||
CP1 & CP2 & CP3 & CPN --> RT
|
||||
RT --> SK --> ACP_SM
|
||||
WS --> AUTH --> PROTO --> ACP_SVR
|
||||
ACP_SVR --> ACP_TR --> ACP_SM
|
||||
ACP_SM --> PI
|
||||
PI --> TC & SKL & SA
|
||||
PI --> MM
|
||||
MM --> VEC & FTS
|
||||
VEC & FTS --> EMB
|
||||
PI --> AP --> CLAUDE & GPT & GEM & QWEN & OL & MORE_LLM
|
||||
PI --> SS
|
||||
HB --> HMD --> PI
|
||||
ACP_SM --> SS
|
||||
|
||||
style WS fill:#4A90D9,color:#fff
|
||||
style PI fill:#E74C3C,color:#fff
|
||||
style MM fill:#27AE60,color:#fff
|
||||
style HB fill:#F39C12,color:#fff
|
||||
style CM fill:#8E44AD,color:#fff
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 三、六大核心子系统详解
|
||||
|
||||
### 3.1 Gateway(通信网关)
|
||||
|
||||
Gateway 是整个系统的**中枢神经**,负责接收所有外部连接、认证设备、路由消息。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Client as 客户端/CLI
|
||||
participant GW as Gateway Server
|
||||
participant Auth as 认证中间件
|
||||
participant Proto as 协议处理器
|
||||
participant CM as Channel Manager
|
||||
participant RT as Route Resolver
|
||||
|
||||
Client->>GW: WebSocket 连接 (ws://localhost:18789)
|
||||
GW->>Auth: 设备认证 (Ed25519 签名)
|
||||
Auth-->>GW: 认证通过 + 设备 Token
|
||||
GW->>Proto: Hello 握手 (PROTOCOL_VERSION)
|
||||
Proto-->>Client: HelloOk (capabilities, scopes)
|
||||
|
||||
Note over Client,RT: 消息流
|
||||
|
||||
Client->>GW: RequestFrame: chat.send
|
||||
GW->>Proto: AJV Schema 校验
|
||||
Proto->>RT: 路由解析 (channel + peer → agent)
|
||||
RT-->>GW: sessionKey + agentId
|
||||
GW->>CM: 分发到对应通道
|
||||
```
|
||||
|
||||
**核心文件:**
|
||||
|
||||
| 文件 | 职责 |
|
||||
|------|------|
|
||||
| `src/gateway/server.impl.ts` | 网关启动入口 `startGatewayServer()` |
|
||||
| `src/gateway/client.ts` | WebSocket 客户端,含重连与退避策略 |
|
||||
| `src/gateway/server-chat.ts` | 聊天消息处理器 |
|
||||
| `src/gateway/protocol/index.ts` | 协议帧定义与 AJV 校验 |
|
||||
| `src/gateway/auth.ts` | 认证中间件 |
|
||||
| `src/gateway/auth-rate-limit.ts` | 速率限制策略 |
|
||||
| `src/gateway/server-channels.ts` | 通道生命周期管理 |
|
||||
|
||||
**Gateway 启动序列:**
|
||||
|
||||
```mermaid
|
||||
graph LR
|
||||
A[加载配置] --> B[校验认证配置]
|
||||
B --> C[初始化 Secrets]
|
||||
C --> D[加载插件]
|
||||
D --> E[创建 Channel Manager]
|
||||
E --> F[初始化 Memory Manager]
|
||||
F --> G[启动 Heartbeat Runner]
|
||||
G --> H[启动 WebSocket Server]
|
||||
H --> I[挂载协议处理器]
|
||||
I --> J[启动 Sidecars<br/>发现/健康监控/Cron]
|
||||
J --> K[✅ Ready]
|
||||
```
|
||||
|
||||
**协议帧类型:**
|
||||
|
||||
| 帧类型 | 方向 | 用途 |
|
||||
|--------|------|------|
|
||||
| `RequestFrame` | Client → Server | chat.send, config.get, sessions.list 等 |
|
||||
| `ResponseFrame` | Server → Client | 请求响应数据 |
|
||||
| `EventFrame` | Server → Client | agent_message, tool_call, usage_update 等 |
|
||||
| `HelloOk` | Server → Client | 握手响应,含协议版本和能力声明 |
|
||||
|
||||
**安全特性:**
|
||||
- **CWE-319 防护**:`isSecureWebSocketUrl()` 禁止非回环地址使用明文 `ws://`
|
||||
- **设备身份**:Ed25519 密钥对存储于 `~/.openclaw/credentials/`
|
||||
- **TLS 指纹**:支持证书指纹验证(Certificate Pinning)
|
||||
- **连接序列号**:检测消息间隙,防止重放攻击
|
||||
|
||||
---
|
||||
|
||||
### 3.2 ACP(Agent Client Protocol 协议层)
|
||||
|
||||
ACP 是 OpenClaw 定义的**标准化 Agent 通信协议**,作为 Gateway 与 Agent 运行时之间的翻译层。
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "ACP 协议栈"
|
||||
EXT[外部 ACP 客户端<br/>stdin/stdout]
|
||||
CONN[AgentSideConnection<br/>ndJSON 流]
|
||||
AGENT[AcpGatewayAgent<br/>协议翻译器]
|
||||
CLIENT[GatewayClient<br/>WebSocket]
|
||||
MGR[AcpSessionManager<br/>会话管理单例]
|
||||
end
|
||||
|
||||
subgraph "运行时缓存"
|
||||
CACHE[RuntimeCache<br/>sessionKey → Handle]
|
||||
QUEUE[ActorQueue<br/>每会话串行化]
|
||||
EVICT[空闲驱逐<br/>TTL 超时清理]
|
||||
end
|
||||
|
||||
EXT --> CONN --> AGENT --> CLIENT
|
||||
AGENT --> MGR
|
||||
MGR --> CACHE & QUEUE
|
||||
CACHE --> EVICT
|
||||
```
|
||||
|
||||
**AcpGatewayAgent 核心职责:**
|
||||
- 翻译 ACP 协议 ↔ Gateway 协议
|
||||
- 管理会话生命周期(initialize → prompt → response)
|
||||
- 速率限制(默认 120 请求 / 10 秒窗口)
|
||||
- 追踪待处理的 prompt 和 tool call
|
||||
|
||||
**AcpSessionManager 核心职责:**
|
||||
- 所有 ACP 运行时会话的单例管理器
|
||||
- 运行时缓存(空闲 TTL 驱逐)
|
||||
- 活跃回合与延迟统计
|
||||
- **Actor 队列**:防止对同一会话的并发写入
|
||||
|
||||
**会话键格式:**
|
||||
|
||||
```
|
||||
@main → 默认主会话
|
||||
@jane → 名为 "jane" 的 Agent 会话
|
||||
$subagent-id:child-key → 子 Agent 会话
|
||||
thread:123 → 线程绑定会话
|
||||
acp:uuid → ACP/IDE 会话
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 3.3 Agent Runtime(Agent 运行时)
|
||||
|
||||
Agent 运行时是系统的**大脑**,负责 LLM 推理、工具调用、子 Agent 调度。
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "Agent 运行时"
|
||||
PI[Pi Agent Runner<br/>核心推理引擎]
|
||||
|
||||
subgraph "模型集成"
|
||||
MC[Model Catalog<br/>模型目录]
|
||||
AP[Auth Profiles<br/>凭证管理]
|
||||
FB[Fallback Chains<br/>模型降级链]
|
||||
TH[Thinking Mode<br/>思考/推理模式]
|
||||
end
|
||||
|
||||
subgraph "工具系统"
|
||||
TC[Tool Catalog]
|
||||
T1[web_search 网络搜索]
|
||||
T2[browser_tool 浏览器]
|
||||
T3[system.run 终端执行]
|
||||
T4[system.spawn_acp 子Agent]
|
||||
T5[channel actions 通道操作]
|
||||
end
|
||||
|
||||
subgraph "技能系统"
|
||||
SL[Skill Loader<br/>jiti 动态导入]
|
||||
SF[skill.json 元数据]
|
||||
SH[skill.ts 运行时处理器]
|
||||
end
|
||||
|
||||
subgraph "子 Agent"
|
||||
SR[Subagent Registry]
|
||||
SP[Spawn ACP<br/>隔离会话派生]
|
||||
end
|
||||
end
|
||||
|
||||
PI --> MC --> AP --> FB
|
||||
PI --> TC --> T1 & T2 & T3 & T4 & T5
|
||||
PI --> SL --> SF & SH
|
||||
PI --> SR --> SP
|
||||
MC --> TH
|
||||
|
||||
subgraph "LLM 提供商"
|
||||
L1[Anthropic Claude]
|
||||
L2[OpenAI GPT]
|
||||
L3[Google Gemini]
|
||||
L4[Qwen 通义千问]
|
||||
L5[Ollama 本地]
|
||||
L6[Groq / Grok / Azure / Minimax / 火山引擎]
|
||||
end
|
||||
|
||||
FB --> L1 & L2 & L3 & L4 & L5 & L6
|
||||
```
|
||||
|
||||
**支持的 LLM 提供商(10+):**
|
||||
|
||||
| 提供商 | 说明 |
|
||||
|--------|------|
|
||||
| Anthropic | Claude Opus / Sonnet / Haiku |
|
||||
| OpenAI | GPT 系列 |
|
||||
| Google | Gemini 系列 |
|
||||
| Qwen | 通义千问(阿里) |
|
||||
| Minimax | 国产大模型 |
|
||||
| Ollama | 本地部署任意开源模型 |
|
||||
| Groq | 高速推理 |
|
||||
| Grok | xAI |
|
||||
| Azure | Azure OpenAI Service |
|
||||
| Volc | 火山引擎(字节) |
|
||||
|
||||
**模型降级链(Fallback Chains):** 当主模型不可用时,自动切换到备用模型,保证服务连续性。
|
||||
|
||||
**工具审批机制:**
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Agent as Agent Runtime
|
||||
participant EA as ExecApprovalManager
|
||||
participant Admin as 管理员
|
||||
participant CMD as 命令执行
|
||||
|
||||
Agent->>EA: system.run("rm -rf /tmp/data")
|
||||
EA->>EA: 检查是否为危险操作
|
||||
EA->>Admin: 显示审批请求
|
||||
Admin-->>EA: ✅ 批准 / ❌ 拒绝
|
||||
alt 批准
|
||||
EA->>CMD: 执行命令
|
||||
CMD-->>Agent: 返回结果
|
||||
else 拒绝
|
||||
EA-->>Agent: 操作被拒绝
|
||||
end
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
### 3.4 Plugin System(插件系统)
|
||||
|
||||
插件系统是 OpenClaw 可扩展性的核心——所有通道集成、记忆后端、诊断工具都以插件形式存在。
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "插件生命周期"
|
||||
D[1. Discovery 发现<br/>扫描 extensions/ 目录]
|
||||
M[2. Manifest 加载<br/>读取 openclaw.plugin.json]
|
||||
R[3. Runtime 创建<br/>初始化 Hook Runner]
|
||||
REG[4. Registration 注册<br/>setActivePluginRegistry]
|
||||
end
|
||||
|
||||
D --> M --> R --> REG
|
||||
|
||||
subgraph "插件类型"
|
||||
CH[通道插件 ×34<br/>Telegram/Slack/Discord/...]
|
||||
MEM[记忆插件<br/>memory-core / memory-lancedb]
|
||||
AUTH_P[认证插件<br/>google-gemini-cli-auth 等]
|
||||
DIAG[诊断插件<br/>diagnostics-otel]
|
||||
SPEC[特殊插件<br/>thread-ownership / llm-task]
|
||||
end
|
||||
|
||||
REG --> CH & MEM & AUTH_P & DIAG & SPEC
|
||||
```
|
||||
|
||||
**已包含的 34 个通道插件:**
|
||||
|
||||
| 类别 | 插件 |
|
||||
|------|------|
|
||||
| 即时通讯 | Telegram, WhatsApp, Signal, iMessage, Line, Zalo |
|
||||
| 团队协作 | Slack, Discord, MS Teams, Mattermost, Google Chat, 飞书 |
|
||||
| 社交/社区 | Matrix, IRC, Nostr, Twitch, Tlon |
|
||||
| 企业通讯 | Synology Chat, Nextcloud Talk, BlueBubbles |
|
||||
| 语音 | voice-call |
|
||||
| 开发/集成 | acpx, copilot-proxy, lobster |
|
||||
|
||||
**Plugin Runtime API:**
|
||||
|
||||
```typescript
|
||||
PluginRuntime = {
|
||||
subagent: {
|
||||
run(), // 运行子 Agent
|
||||
waitForRun(), // 等待运行完成
|
||||
getSessionMessages(),
|
||||
deleteSession()
|
||||
},
|
||||
channel: {
|
||||
list(), // 列出通道
|
||||
inspect(), // 检查通道状态
|
||||
sendMessage() // 发送消息
|
||||
},
|
||||
core: {
|
||||
config, // 全局配置
|
||||
workspaceDir, // 工作区目录
|
||||
agentId // 当前 Agent ID
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**Hook 系统:**
|
||||
|
||||
| Hook | 触发时机 |
|
||||
|------|---------|
|
||||
| `gateway.startup()` | 网关启动时 |
|
||||
| `gateway.shutdown()` | 优雅关闭时 |
|
||||
| `channel.ready()` | 通道连接就绪 |
|
||||
| `channel.message()` | 收到消息时 |
|
||||
| `session.start()` | 会话开始 |
|
||||
| `session.prompt()` | LLM 推理前 |
|
||||
| `session.response()` | LLM 响应后 |
|
||||
|
||||
---
|
||||
|
||||
### 3.5 Memory System(记忆系统)
|
||||
|
||||
记忆系统实现了**向量检索 + BM25 全文搜索**的混合搜索架构,是 Agent 长期记忆的基础。
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "记忆系统架构"
|
||||
Q[搜索查询]
|
||||
|
||||
subgraph "混合搜索引擎"
|
||||
VS[向量检索<br/>sqlite-vec]
|
||||
BM[BM25 全文搜索<br/>SQLite FTS5]
|
||||
HY[混合排序<br/>加权合并 + 时间衰减]
|
||||
end
|
||||
|
||||
subgraph "Embedding 提供商"
|
||||
E1[OpenAI<br/>text-embedding-3-small/large]
|
||||
E2[Gemini<br/>Generalist Multimodal]
|
||||
E3[Voyage<br/>voyage-large-2-instruct]
|
||||
E4[Mistral<br/>mistral-embed]
|
||||
E5[Ollama<br/>本地模型]
|
||||
end
|
||||
|
||||
subgraph "存储层"
|
||||
DB[(SQLite 数据库)]
|
||||
CV[chunks_vec 表<br/>向量嵌入]
|
||||
CF[chunks_fts 表<br/>FTS5 全文索引]
|
||||
EC[embedding_cache 表<br/>查询缓存 + TTL]
|
||||
end
|
||||
|
||||
RES[搜索结果<br/>相关度排序]
|
||||
end
|
||||
|
||||
Q --> VS & BM
|
||||
VS --> HY
|
||||
BM --> HY
|
||||
VS --> E1 & E2 & E3 & E4 & E5
|
||||
E1 & E2 & E3 & E4 & E5 --> CV
|
||||
BM --> CF
|
||||
HY --> RES
|
||||
DB --> CV & CF & EC
|
||||
|
||||
style HY fill:#27AE60,color:#fff
|
||||
style DB fill:#3498DB,color:#fff
|
||||
```
|
||||
|
||||
**MemoryIndexManager 是单例模式**,每个 Agent + Workspace 一个实例:
|
||||
|
||||
```typescript
|
||||
// 获取或创建记忆管理器
|
||||
const memory = await MemoryIndexManager.get({
|
||||
cfg: config,
|
||||
agentId: "main",
|
||||
purpose: "chat"
|
||||
});
|
||||
|
||||
// 混合搜索
|
||||
const results = await memory.search({
|
||||
query: "用户上周提到的跑步习惯",
|
||||
limit: 10,
|
||||
threshold: 0.7,
|
||||
hybrid: { weight: 0.6 } // 向量权重 60%, BM25 权重 40%
|
||||
});
|
||||
```
|
||||
|
||||
**关键特性:**
|
||||
- **时间衰减**:近期记忆权重更高
|
||||
- **批量嵌入**:失败自动恢复
|
||||
- **查询缓存**:TTL 控制的 embedding 缓存层
|
||||
- **额外记忆路径**:可引入外部文档目录
|
||||
|
||||
---
|
||||
|
||||
### 3.6 Heartbeat(心跳机制)
|
||||
|
||||
心跳是 OpenClaw 最具争议也最核心的设计——让 AI **主动醒来执行任务**,而不是被动等待指令。
|
||||
|
||||
```mermaid
|
||||
sequenceDiagram
|
||||
participant Timer as 定时器 (默认 30 分钟)
|
||||
participant HB as Heartbeat Runner
|
||||
participant FS as 文件系统
|
||||
participant Agent as Agent Runtime
|
||||
participant LLM as LLM 提供商
|
||||
participant Channel as 消息通道
|
||||
|
||||
loop 每 30 分钟
|
||||
Timer->>HB: 触发心跳
|
||||
HB->>FS: 读取 HEARTBEAT.md
|
||||
alt HEARTBEAT.md 为空或不存在
|
||||
HB->>HB: 跳过,不调用 API
|
||||
else HEARTBEAT.md 有任务内容
|
||||
HB->>Agent: 发送 HEARTBEAT_PROMPT
|
||||
Agent->>LLM: 推理 + 任务执行
|
||||
LLM-->>Agent: 执行结果
|
||||
alt 返回 HEARTBEAT_OK
|
||||
Agent-->>HB: 无需操作,静默
|
||||
else 有实际输出
|
||||
Agent->>Channel: 发送结果到通道
|
||||
Channel-->>HB: 显示 ACK 反应 (👀)
|
||||
end
|
||||
end
|
||||
end
|
||||
```
|
||||
|
||||
**HEARTBEAT.md 示例:**
|
||||
|
||||
```markdown
|
||||
## 每日任务
|
||||
|
||||
- 每天早上 9:00 检查未读邮件,分类后发送摘要到 Slack #daily
|
||||
- 监控竞品价格变动,降幅超过 10% 立即通知
|
||||
- 每周五下午生成本周工作总结
|
||||
|
||||
## 触发条件
|
||||
|
||||
- 仅在工作日执行
|
||||
- 静默模式:无变化时不发送消息
|
||||
```
|
||||
|
||||
**可见性控制:**
|
||||
|
||||
| 配置项 | 说明 | 默认值 |
|
||||
|--------|------|--------|
|
||||
| `heartbeat.every` | 心跳间隔 | 30m |
|
||||
| `heartbeat.enabled` | 是否启用 | true |
|
||||
| `heartbeat.ackMaxChars` | ACK 最大字符数 | 300 |
|
||||
| `SILENT_REPLY_TOKEN` | 静默回复标记 | #SILENT_ACK |
|
||||
| `HEARTBEAT_OK` | 无需操作标记 | HEARTBEAT_OK |
|
||||
|
||||
---
|
||||
|
||||
## 四、数据流全链路
|
||||
|
||||
一条消息从外部平台进入到最终响应,经过的完整链路:
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "① 消息接收"
|
||||
MSG[用户消息<br/>Telegram/Slack/...]
|
||||
SDK[平台 SDK<br/>原生协议接收]
|
||||
NORM[消息标准化<br/>统一格式]
|
||||
end
|
||||
|
||||
subgraph "② 路由决策"
|
||||
RT[Route Resolver<br/>channel + peer → agentId]
|
||||
BIND[Session Binding<br/>会话绑定服务]
|
||||
SK[Session Key<br/>生成会话键]
|
||||
end
|
||||
|
||||
subgraph "③ 会话管理"
|
||||
ACP[ACP Session Manager]
|
||||
LOCK[Session Write Lock<br/>防并发写入]
|
||||
LOAD[加载会话历史<br/>JSONL 转录]
|
||||
end
|
||||
|
||||
subgraph "④ Agent 推理"
|
||||
PI[Pi Agent Runner]
|
||||
LLM[LLM API 调用<br/>含 Thinking Mode]
|
||||
TOOL[工具调用<br/>审批 → 执行]
|
||||
MEM[记忆检索<br/>混合搜索]
|
||||
end
|
||||
|
||||
subgraph "⑤ 响应投递"
|
||||
STREAM[流式响应<br/>逐 Token 返回]
|
||||
TRANS[格式转换<br/>适配目标平台]
|
||||
DELIVER[投递到通道<br/>支持线程/回复]
|
||||
PERSIST[持久化<br/>会话 + 记忆写入]
|
||||
end
|
||||
|
||||
MSG --> SDK --> NORM
|
||||
NORM --> RT --> BIND --> SK
|
||||
SK --> ACP --> LOCK --> LOAD
|
||||
LOAD --> PI --> LLM
|
||||
LLM --> TOOL
|
||||
TOOL --> MEM
|
||||
LLM --> STREAM --> TRANS --> DELIVER
|
||||
DELIVER --> PERSIST
|
||||
|
||||
style MSG fill:#9B59B6,color:#fff
|
||||
style PI fill:#E74C3C,color:#fff
|
||||
style DELIVER fill:#2ECC71,color:#fff
|
||||
```
|
||||
|
||||
---
|
||||
|
||||
## 五、持久化与存储架构
|
||||
|
||||
```mermaid
|
||||
graph LR
|
||||
subgraph "~/.openclaw/ 存储结构"
|
||||
subgraph "设备层"
|
||||
DI[device-identity.json<br/>Ed25519 密钥对]
|
||||
CRED[credentials/<br/>设备 Token]
|
||||
end
|
||||
|
||||
subgraph "配置层"
|
||||
CONFIG[config.json<br/>全局配置]
|
||||
SECRETS[secrets/<br/>API Key 引用]
|
||||
end
|
||||
|
||||
subgraph "Agent 层 (per-agent)"
|
||||
subgraph "agents/main/"
|
||||
SESS[sessions.json<br/>会话元数据]
|
||||
TRANS[sessions/*.jsonl<br/>会话转录]
|
||||
WS[workspace/<br/>工作区文件]
|
||||
HMD2[HEARTBEAT.md]
|
||||
MEMDB[memory.sqlite<br/>向量+全文索引]
|
||||
end
|
||||
end
|
||||
end
|
||||
|
||||
style DI fill:#E67E22,color:#fff
|
||||
style CONFIG fill:#3498DB,color:#fff
|
||||
style SESS fill:#2ECC71,color:#fff
|
||||
style MEMDB fill:#9B59B6,color:#fff
|
||||
```
|
||||
|
||||
**会话存储细节:**
|
||||
|
||||
| 存储项 | 格式 | 说明 |
|
||||
|--------|------|------|
|
||||
| 会话元数据 | JSON | 模型、Token 用量、思考级别等 |
|
||||
| 会话转录 | JSONL (追加写入) | 不可变的消息日志,按大小/数量自动轮转 |
|
||||
| 记忆索引 | SQLite | 向量表 + FTS 表 + 缓存表 |
|
||||
| 设备身份 | JSON | Ed25519 公私钥对 |
|
||||
| 配置 | JSON | 全局配置,含 Secret 引用 |
|
||||
|
||||
**Secrets 引用机制:**
|
||||
|
||||
```json
|
||||
{
|
||||
"providers": {
|
||||
"anthropic": {
|
||||
"apiKey": "${file://~/.openclaw/secrets/anthropic.key}"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
支持 `${file://path}` 和 `${env://VAR_NAME}` 两种引用方式。
|
||||
|
||||
---
|
||||
|
||||
## 六、安全架构
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "安全层级"
|
||||
subgraph "L1: 网络层"
|
||||
TLS[TLS/mTLS 加密]
|
||||
FP[证书指纹验证]
|
||||
CWE[CWE-319 防护<br/>禁止明文WS到非回环]
|
||||
end
|
||||
|
||||
subgraph "L2: 认证层"
|
||||
DEV[设备认证<br/>Ed25519 签名]
|
||||
TOKEN[设备 Token<br/>长期访问令牌]
|
||||
OAUTH[OAuth 集成<br/>Google/Discord 等]
|
||||
PWD[密码认证<br/>本地网关备选]
|
||||
end
|
||||
|
||||
subgraph "L3: 授权层"
|
||||
SCOPE[操作域 Scopes]
|
||||
PAIR[设备配对审批]
|
||||
ROLE[Owner vs User 角色]
|
||||
end
|
||||
|
||||
subgraph "L4: 执行层"
|
||||
APPROVE[工具审批门<br/>危险操作拦截]
|
||||
SANDBOX[沙箱策略<br/>inherit/require/forbidden]
|
||||
AUDIT[审计日志]
|
||||
SCAN[危险工具扫描]
|
||||
end
|
||||
end
|
||||
|
||||
TLS --> DEV --> SCOPE --> APPROVE
|
||||
FP --> TOKEN --> PAIR --> SANDBOX
|
||||
CWE --> OAUTH --> ROLE --> AUDIT
|
||||
PWD --> SCAN
|
||||
```
|
||||
|
||||
**操作域(Scopes)细粒度控制:**
|
||||
|
||||
| Scope | 权限 |
|
||||
|-------|------|
|
||||
| `gateway:full` | 网关完全控制 |
|
||||
| `gateway:read` | 只读访问 |
|
||||
| `channels:read` | 读取通道信息 |
|
||||
| `messages:send` | 发送消息 |
|
||||
| `config:write` | 修改配置 |
|
||||
| `agents:manage` | Agent 管理 |
|
||||
|
||||
**沙箱策略:**
|
||||
|
||||
| 策略 | 说明 |
|
||||
|------|------|
|
||||
| `inherit` | 继承父会话沙箱模式 |
|
||||
| `require` | 强制更严格的沙箱 |
|
||||
| `forbidden` | 禁止子 Agent 派生 |
|
||||
|
||||
**安全审计(`src/security/`):**
|
||||
- `dangerous-tools.ts` — 危险工具扫描器
|
||||
- `dangerous-config-flags.ts` — 危险配置标记检测
|
||||
- `audit.ts` — 审计日志记录器
|
||||
- 临时路径防护、外部内容策略
|
||||
|
||||
---
|
||||
|
||||
## 七、通道集成架构
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "通道插件架构"
|
||||
IF[ChannelPlugin 接口]
|
||||
|
||||
subgraph "插件实现"
|
||||
TG[Telegram<br/>Bot API]
|
||||
SL[Slack<br/>Bolt SDK]
|
||||
DC[Discord<br/>discord.js]
|
||||
WA[WhatsApp<br/>Baileys]
|
||||
SIG[Signal<br/>signal-cli]
|
||||
FS[飞书<br/>Open API]
|
||||
end
|
||||
|
||||
subgraph "生命周期"
|
||||
INIT[initialize<br/>认证 + 连接]
|
||||
LISTEN[listen<br/>消息监听]
|
||||
ROUTE[route<br/>路由到 Agent]
|
||||
DELIVER[deliver<br/>回传响应]
|
||||
SHUTDOWN[shutdown<br/>优雅断开]
|
||||
end
|
||||
end
|
||||
|
||||
IF --> TG & SL & DC & WA & SIG & FS
|
||||
TG & SL & DC & WA & SIG & FS --> INIT --> LISTEN --> ROUTE --> DELIVER --> SHUTDOWN
|
||||
```
|
||||
|
||||
**通道插件必须实现的接口:**
|
||||
|
||||
```typescript
|
||||
interface ChannelPlugin {
|
||||
// 配置 Schema 定义
|
||||
configSchema: JSONSchema;
|
||||
|
||||
// 生命周期
|
||||
initialize(config: ChannelConfig): Promise<void>;
|
||||
shutdown(): Promise<void>;
|
||||
|
||||
// 消息处理
|
||||
onMessage(handler: MessageHandler): void;
|
||||
sendMessage(target: Target, message: Message): Promise<void>;
|
||||
|
||||
// 状态
|
||||
getStatus(): ChannelStatus;
|
||||
getAccounts(): AccountInfo[];
|
||||
}
|
||||
```
|
||||
|
||||
**消息标准化:** 所有通道的消息都会被标准化为统一格式,包括:
|
||||
- 文本内容
|
||||
- 附件(图片/文件/音频)
|
||||
- 发送者身份
|
||||
- 线程/回复关系
|
||||
- 通道特定元数据
|
||||
|
||||
---
|
||||
|
||||
## 八、构建与部署
|
||||
|
||||
### 8.1 Docker 部署架构
|
||||
|
||||
```mermaid
|
||||
graph TB
|
||||
subgraph "Docker Compose"
|
||||
GW_SVC[gateway 服务<br/>Node.js 运行时]
|
||||
CLI_SVC[cli 服务<br/>命令行交互]
|
||||
HC[健康检查<br/>端口 18789]
|
||||
end
|
||||
|
||||
subgraph "Docker 镜像"
|
||||
BASE[Dockerfile<br/>多阶段构建]
|
||||
SB[Dockerfile.sandbox<br/>沙箱镜像]
|
||||
SBB[Dockerfile.sandbox-browser<br/>浏览器沙箱]
|
||||
SBC[Dockerfile.sandbox-common<br/>公共沙箱基础]
|
||||
end
|
||||
|
||||
subgraph "其他部署"
|
||||
FLY[fly.toml<br/>Fly.io 部署]
|
||||
RENDER[render.yaml<br/>Render 部署]
|
||||
PODMAN[Podman<br/>无 root 容器]
|
||||
end
|
||||
|
||||
GW_SVC --> BASE
|
||||
CLI_SVC --> BASE
|
||||
GW_SVC --> HC
|
||||
BASE --> SB & SBB & SBC
|
||||
```
|
||||
|
||||
### 8.2 发布通道
|
||||
|
||||
| 通道 | 版本格式 | npm dist-tag |
|
||||
|------|---------|--------------|
|
||||
| Stable | vYYYY.M.D | `latest` |
|
||||
| Beta | vYYYY.M.D-beta.N | `beta` |
|
||||
| Dev | main 分支 | 无 tag |
|
||||
|
||||
### 8.3 客户端矩阵
|
||||
|
||||
| 平台 | 技术栈 | 位置 |
|
||||
|------|--------|------|
|
||||
| CLI | Commander.js + Clack | `src/cli/` |
|
||||
| Web UI | React + Vite | `ui/` |
|
||||
| macOS | SwiftUI + XPC Bridge | `apps/macos/` |
|
||||
| iOS | React Native | `apps/ios/` |
|
||||
| Android | React Native | `apps/android/` |
|
||||
|
||||
---
|
||||
|
||||
## 九、关键设计模式总结
|
||||
|
||||
### 9.1 架构模式
|
||||
|
||||
```mermaid
|
||||
mindmap
|
||||
root((OpenClaw<br/>设计模式))
|
||||
消息驱动
|
||||
WebSocket 双向通信
|
||||
EventFrame 事件流
|
||||
RequestFrame 请求/响应
|
||||
插件化
|
||||
34 个通道插件
|
||||
Hook 系统 7 个钩子
|
||||
动态加载 jiti
|
||||
会话隔离
|
||||
Actor 队列串行化
|
||||
Session Write Lock
|
||||
Per-agent 存储隔离
|
||||
安全纵深
|
||||
L1 网络加密
|
||||
L2 设备认证
|
||||
L3 域控授权
|
||||
L4 执行审批
|
||||
韧性设计
|
||||
模型降级链
|
||||
连接重试退避
|
||||
嵌入失败恢复
|
||||
```
|
||||
|
||||
### 9.2 核心设计决策
|
||||
|
||||
| 决策 | 选择 | 理由 |
|
||||
|------|------|------|
|
||||
| 协议 | WebSocket + 自定义协议 | 双向实时通信,低延迟 |
|
||||
| 存储 | 文件系统 + SQLite | 零外部依赖,本地优先 |
|
||||
| 插件加载 | jiti 动态导入 | 支持 TypeScript 直接加载,无需预编译 |
|
||||
| 并发控制 | Actor 队列 | 避免锁竞争,每会话串行保证一致性 |
|
||||
| 记忆检索 | 向量 + BM25 混合 | 语义理解 + 精确匹配,互补短板 |
|
||||
| 安全模型 | 设备身份 + Scopes | 零信任架构,最小权限原则 |
|
||||
| 心跳 | 文件驱动 (HEARTBEAT.md) | 无需额外调度基础设施,用户可直接编辑 |
|
||||
|
||||
### 9.3 值得关注的工程亮点
|
||||
|
||||
1. **协议翻译器模式(ACP Translator)**:将外部标准协议与内部网关协议解耦,允许独立演进
|
||||
2. **运行时缓存 + 空闲驱逐**:会话不用时自动回收资源,用时自动恢复
|
||||
3. **Secret 引用而非内联**:配置文件中不存储明文密钥,而是引用外部文件或环境变量
|
||||
4. **会话转录追加写入**:不可变日志,天然支持故障恢复和审计
|
||||
5. **嵌入提供商可替换**:同一套记忆系统可无缝切换 OpenAI、Gemini、本地 Ollama 等后端
|
||||
|
||||
---
|
||||
|
||||
## 十、架构风险与局限
|
||||
|
||||
| 风险点 | 说明 | 影响 |
|
||||
|--------|------|------|
|
||||
| **明文 Markdown 存储** | HEARTBEAT.md、MEMORY.md 等以明文存储 | API Key 泄露风险 |
|
||||
| **Root 级终端权限** | `system.run` 工具可执行任意命令 | 需依赖审批机制,但默认可绕过 |
|
||||
| **心跳无人值守** | Agent 可在用户不知情时自主行动 | MoltMatch 等事件的根因 |
|
||||
| **第三方 Skill 生态** | ClawHub 26% 插件含漏洞/恶意代码 | 供应链攻击面 |
|
||||
| **单体网关** | Gateway 是单点,承载所有通道 | 高可用需额外架构 |
|
||||
| **文件系统依赖** | 会话存储依赖本地文件系统 | 不原生支持分布式部署 |
|
||||
|
||||
---
|
||||
|
||||
> **总结**:OpenClaw 的架构本质上是一个**面向消息的分布式系统**——Gateway 是交换机,Agent 是 LLM 驱动的任务执行器,Channel 是双向传输管道。记忆、安全和可扩展性是一等公民,而非事后补丁。但其"本地优先"的设计哲学也带来了明文存储和单点依赖的固有风险。
|
||||