- 014 字节又整大活:给AI配了云电脑+云手机 - 015 七天连撩三颗王炸:GPT-5.5、DeepSeek V4、Claude 4.7 混战 - 016 Loop Engineering 保姆级指南 - 补全 doc/passport/image2图片生成.md:WhatAI 图像生成技能文档 - CLAUDE.md 增加 AI 图片生成规范说明 - 删除过时的 open-source-code/openclaw-arch-by-claude.md Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
19 KiB
还在手敲 Prompt?Claude Code 之父:我的工作就是写循环!Loop Engineering 保姆级指南
发布日期:2026-06-12 分类:技术指南 / AI 工程 作者:老邓唠AI
这几天技术圈被一个新词刷屏了:Loop Engineering(循环工程)。
起因是 6 月 7 日,开发者圈的老熟人 Peter Steinberger 在 X 上发了一句话:"你不应该再手动给编程智能体写提示词了,你应该设计循环,让循环去提示你的智能体。"第二天,Google 的工程大佬 Addy Osmani(写《JavaScript 设计模式》那位)直接跟了一篇长文,标题就叫《Loop Engineering》。更狠的是 Anthropic 的 Claude Code 负责人 Boris Cherny,他的原话是:
"我已经不直接提示 Claude 了。我有一堆循环在跑,它们负责提示 Claude、决定接下来做什么。我的工作就是写循环。"
做出全世界最火 AI 编程工具的人,自己都不写 prompt 了。
我花了三个晚上,把 Addy Osmani 的原文和社区里能找到的资料都啃了一遍,又在自己的项目上实际跑了两个小循环,今天就用大白话和大家聊聊这个东西:它到底是什么、核心原理、六大要素,文章最后还有一个完整的实战案例,配置文件可以直接抄作业。
建议收藏,内容有点长。
什么是 Loop Engineering?
用大白话说:以前是你坐在电脑前,一条一条给 AI 发指令;现在是你设计一个系统,这个系统自己给 AI 发指令,一直干到目标达成为止。
打个比方,你招了个能力很强的实习生:
- 旧玩法:你坐他旁边,说一句他做一步。"改这个 bug",他改完你看一眼,"不对重来",他再来一遍。他干活的每一分钟你都得在场。
- 新玩法:你给他定一套工作制度。每天早上自己去看 bug 列表,挑出能修的修掉,修完自己跑测试,测试过了交给质检员复核,复核过了提交,搞不定的放进"待人工处理"清单。然后你该干嘛干嘛,早上来只看结果。
这套"工作制度"就是循环(Loop),设计这套制度的活儿,就是循环工程。
熟悉项目管理的朋友会发现,这其实很像工程学里的 PDCA 循环(计划-执行-检查-处理),只不过转圈的从人变成了 AI。
它和传统模式的差异,我整理了一个表:
| 传统提示模式 | 循环模式 | |
|---|---|---|
| 工作方式 | 一问一答,人盯着 | 系统自动迭代,人看结果 |
| 你的角色 | 提示词工程师 | 规则制定者 |
| 反馈方式 | 你看完手动改提示 | 测试、lint 自动验证 |
| 适合场景 | 短任务、问答 | 复杂、长时间、可验证的任务 |
这是一个挺根本的思维转变:我们的工作不再是写出完美的提示词,而是设计出完美的反馈系统。
AI 编程的三次革命
短短三年,AI 编程已经换了三次玩法,我画了张演进图:
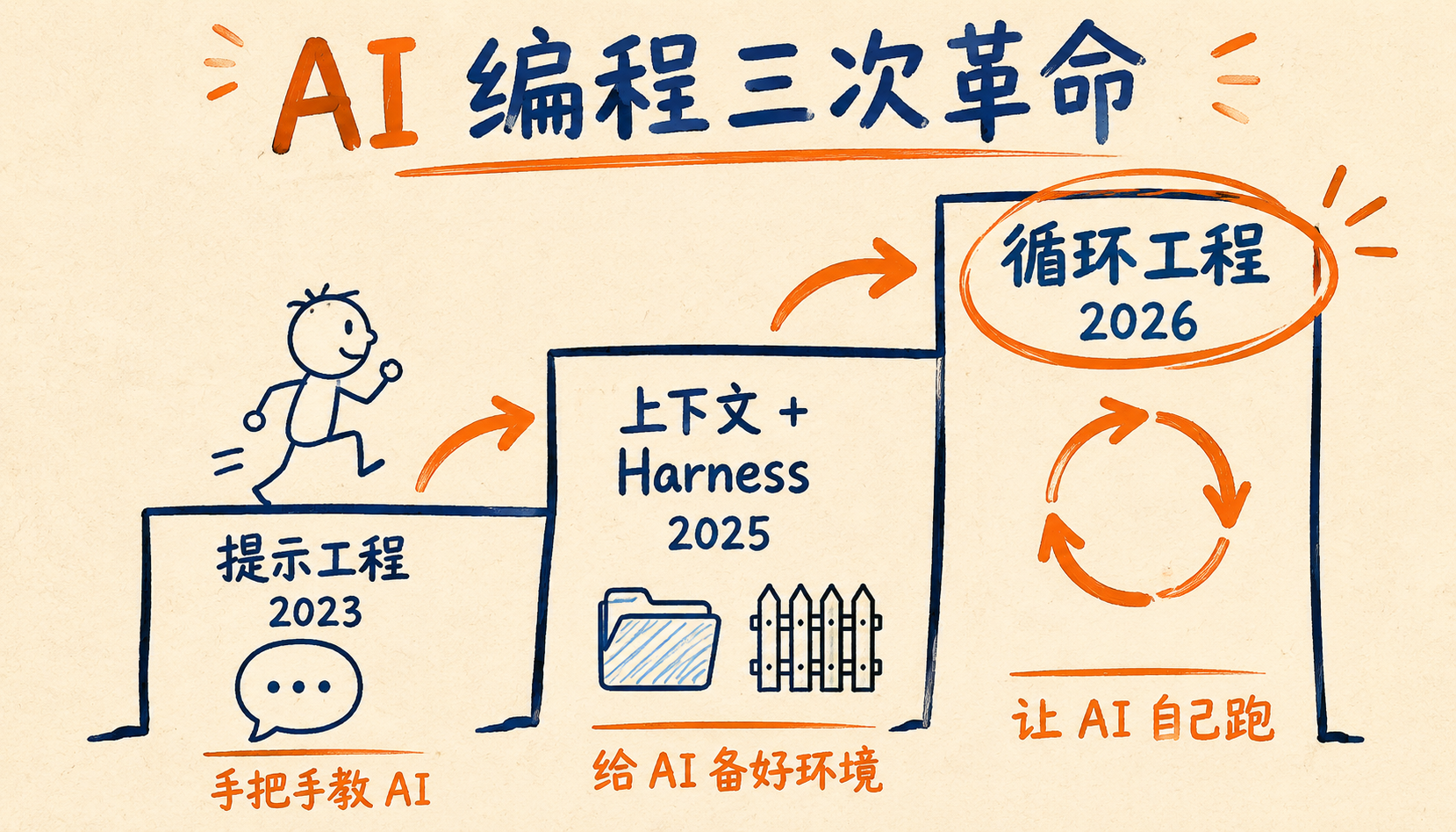
- 提示工程(2023):手把手教 AI。一句话问不好,答案就跑偏,所以那两年"提示词模板"满天飞。
- 上下文工程 + Harness(2025):给 AI 备好环境。RAG、记忆管理、工具调用、沙箱权限,把 AI 圈在一个安全的环境里干活。我 4 月那篇讲 Harness 的文章(《2026 年最火的 Harness 到底是什么鬼》)说的就是这个阶段,没看过的朋友可以翻一下。
- 循环工程(2026):让 AI 自己跑。人从"过程"里退出来,只管定目标和验收。
说实话,前两个阶段已经能解决大部分开发场景了。比如以前要手写的静态官网,现在提示词加上几个 skills,运营同学自己就能搞定;再比如一个后台管理系统,搭好一套成熟的上下文和 Harness,AI 一天能干完 80% 的活,剩下的就是人工测试优化。
Loop Engineering 要砍掉的,就是剩下那部分"人工盯着"的环节。
要注意的是,循环工程不是凭空冒出来的,它站在前面所有技术的肩膀上。我把这套体系总结成四层架构:
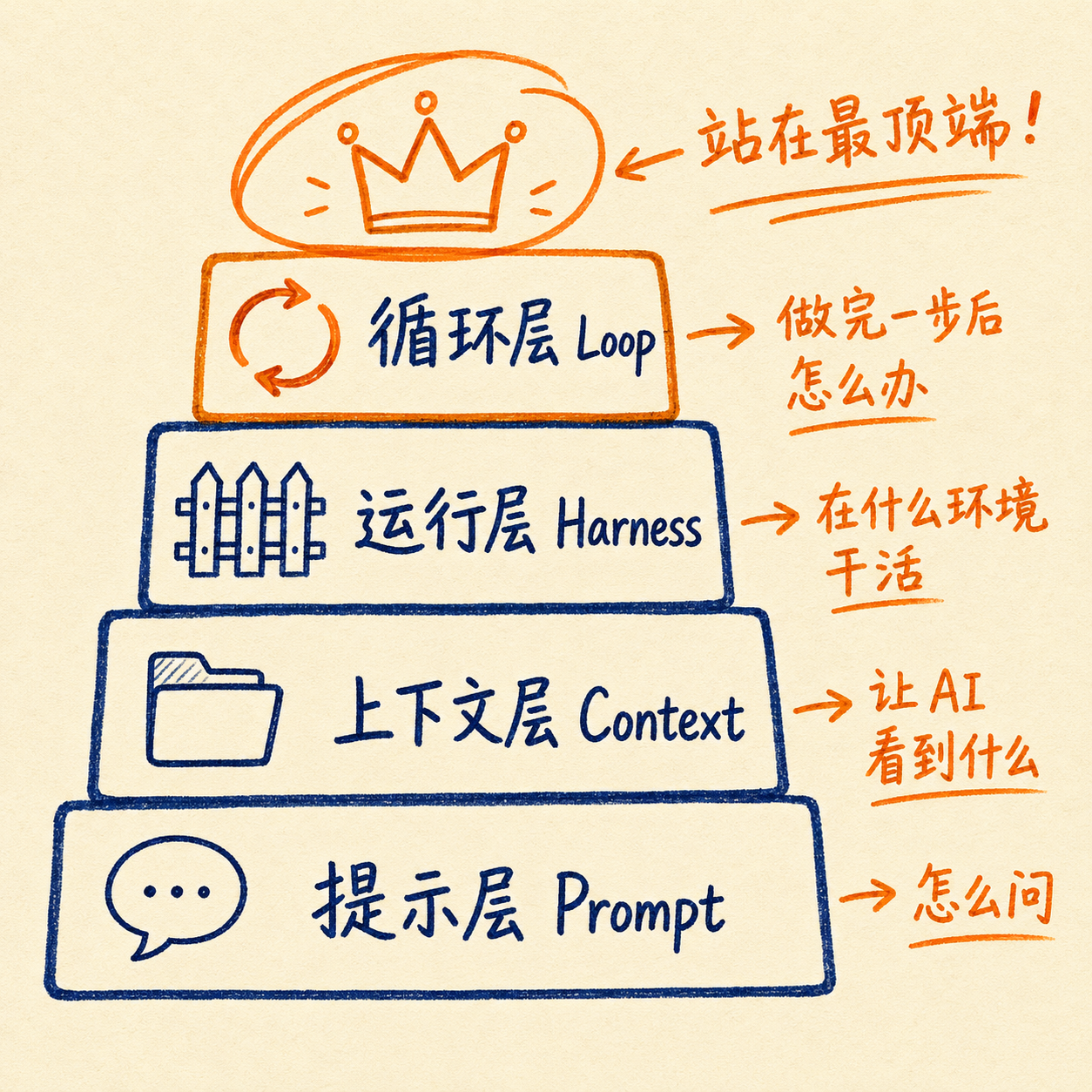
- Prompt 层解决"怎么问":角色设定、输出格式、示例
- Context 层解决"让 AI 看到什么":RAG、记忆管理、文件检索
- Harness 层解决"AI 在什么环境干活":工具调用、沙箱、权限控制
- Loop 层解决"AI 做完一步后怎么办":自动检查、修正、继续还是停止
Loop 层站在最顶端,它关心的不是单次对话的质量,而是整个系统的自运行能力。所以别误会,循环工程不是说提示词没用了,提示词变成了循环里的一个零件。
下面开始上干货。
核心原理:五阶段循环
Addy Osmani 总结过一个通用模型:无论单 Agent 还是多 Agent,一个编码循环都遵循同样的五个阶段,一直转到满足"可验证的停止条件"为止。
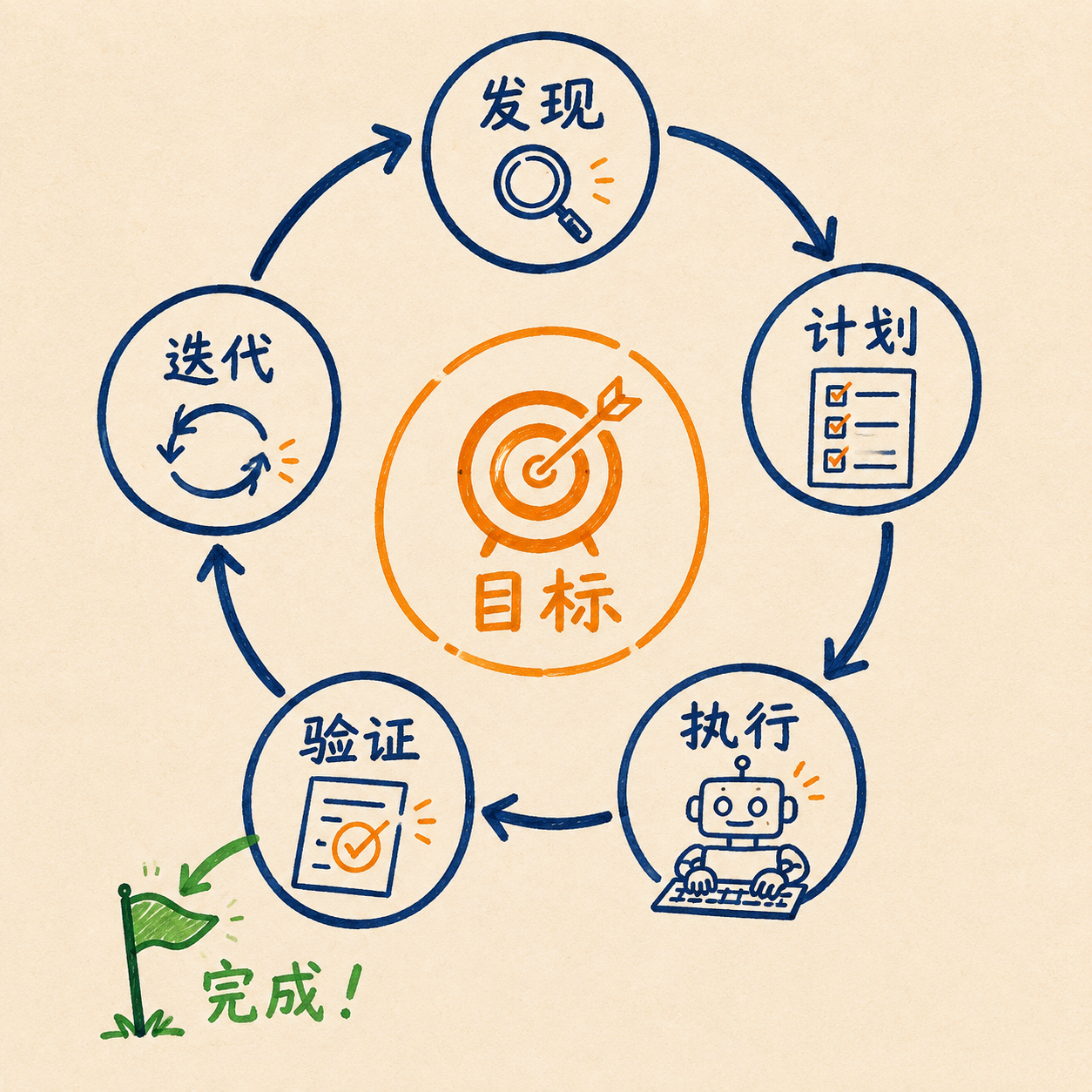
- 发现(Discover):去哪找活儿?CI 失败日志、issue 列表、监控告警
- 计划(Plan):这个活儿怎么拆,先干哪个
- 执行(Execute):读代码、改文件、跑命令
- 验证(Verify):测试过没过?lint 干不干净?这一步必须是客观的,不能让 AI 自己说了算
- 迭代(Iterate):过了就推进下一项,没过就带着错误信息回到第 2 步重试
一个最核心的思想:状态存外面,别信上下文窗口
如果整篇文章只记一句话,记这句。
模型会遗忘,会漂移,上下文一压缩,你之前强调的约束可能就丢了。所以成熟的做法是:所有状态都存在外部系统里——git 仓库、markdown 文件、数据库、issue 系统都行。每次循环迭代都开一个全新的上下文窗口,从磁盘上读状态接着干。
这也是为什么社区里最早出圈的"土法循环"Ralph Loop 影响这么大,它就一行 bash:
while :; do cat PROMPT.md | claude; done
给大家拆解一下:每次循环都重新读 PROMPT.md 和当前代码库的状态,完全不要之前的对话历史。看着简单粗暴,但它恰好绕开了长对话上下文的所有毛病——忘事、漂移、越聊越乱。
(这玩法 2025 年就有人在用了,不过那会儿模型能力不够,跑一晚上基本是白烧钱,现在才算真正能打。)
六大核心要素
Addy Osmani 指出,现在的主流 AI 编程工具(Claude Code、Codex 等)已经把循环工程需要的六大要素全部内置了,不用自己造轮子。理解了这六块积木,你在任何工具里都能搭出循环。
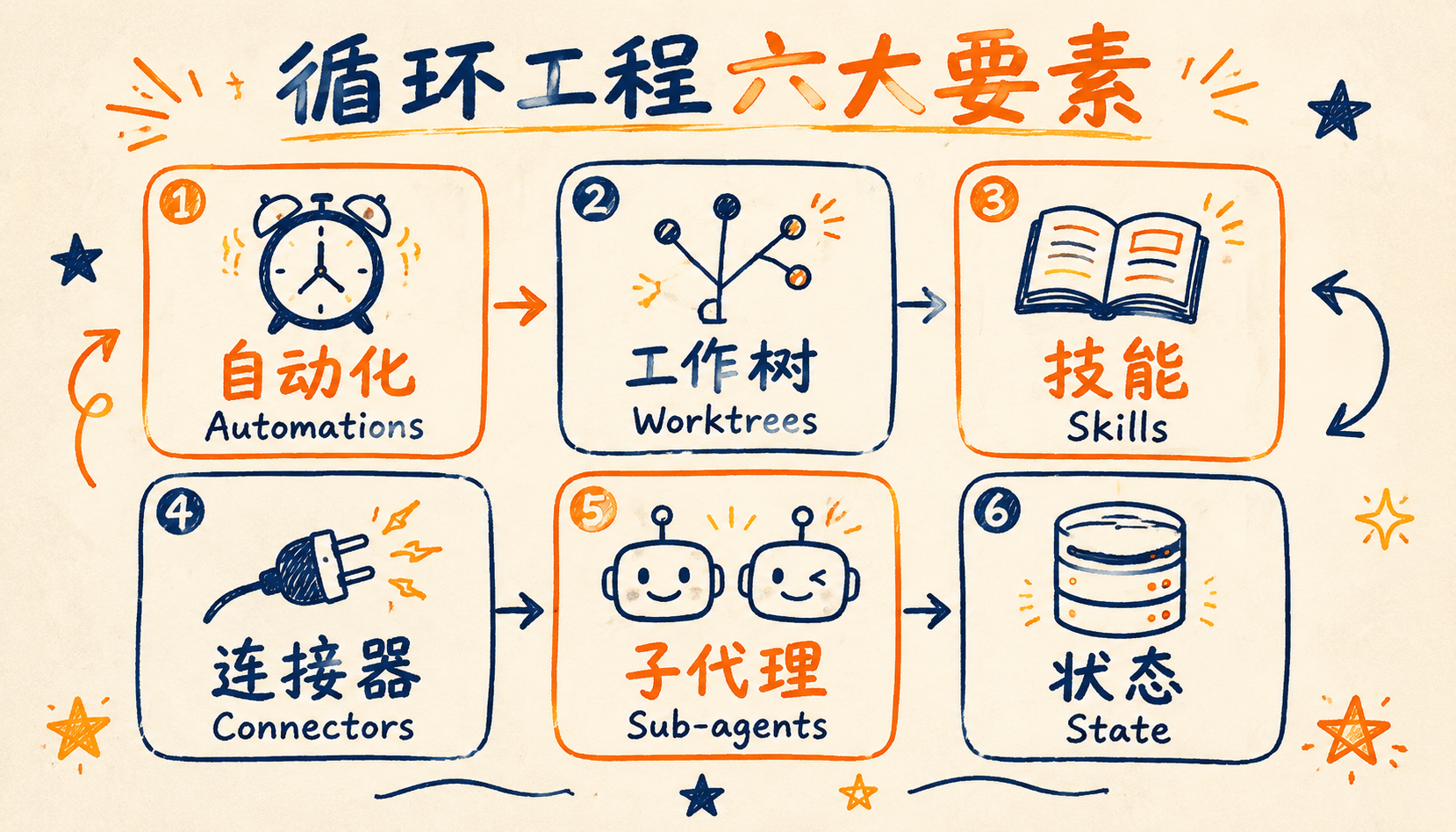
1. 自动化(Automations):让循环真正转起来
没有定时触发,"循环"就只是你手动跑了一次的脚本。自动化决定任务何时运行、多久跑一次。
几个典型场景:
- 每天早上 7 点半,自动处理前一天的 bug
- 每当有新 PR 打开,自动跑一遍代码审查
- 每两小时检查一次性能基准
- 每周五下午自动生成 CHANGELOG
对应到 Claude Code,大概长这样:
# 每天早上 6 点跑一次,分诊昨天的 CI 失败
/loop "用 ci-triage 技能分析昨天的 CI 失败,给能修的开 PR" --schedule "0 6 * * *"
# 一直跑,直到条件为真才停
/goal "test/auth 下所有测试通过,且 lint 零警告"
/goal 有个很妙的设计:每轮结束后由一个独立的小模型来判断"做完了没有",写代码的不给自己打分。Codex 那边对应的是 Automations 标签页加分诊收件箱,原理一样。
2. 工作树(Worktrees):并行干活不打架
同时跑多个 AI,最大的问题是文件冲突——都改同一个目录,必然互相覆盖。Git worktree 给每个 Agent 一个独立的工作目录,共享仓库历史但不共享文件,各干各的,干完再合并。
# 在独立工作树里开一个会话
claude --worktree feature/add-search
我个人理解,这就是把 git 那套多人协作机制,原封不动搬到了多 Agent 协作上。
3. 技能(Skills):经验的复用包
每开一个新会话,AI 就"失忆"一次,你总不能每次都把项目规范从头讲一遍。Skills 就是把项目知识固化到磁盘上:一个文件夹,里面放 SKILL.md、可选脚本和参考资料,AI 需要时自动调用。
它核心解决三个老毛病:
- 每次会话都要重新解释项目结构
- AI 总忘记编码规范
- 同一个错误在不同会话里反复出现
企业级的技能目录一般长这样:
skills/
database/
SKILL.md
scripts/
migrate.sh
references/
schema.md
api/
SKILL.md
testing/
SKILL.md
SKILL.md 写法很朴素,比如:
# 数据库技能
## 我们怎么写数据库代码
- 所有数据库操作走 Knex.js
- 迁移文件统一放 migrations/ 目录
- 每张表必须有 created_at 和 updated_at
- 生产环境永远不要 DROP COLUMN
## 怎么跑迁移
npm run migrate
注意一个细节:技能描述要写得无聊而精确。AI 靠这段描述决定什么时候调用它,写得太"聪明"反而容易误触发。
4. 连接器(Connectors):给循环装上手
连接器基于 MCP 协议,让循环能操作你已经在用的真实工具。它是"AI 告诉你该做什么"和"AI 实际帮你做完了"之间的关键区别。
常见的几类:
- Issue 跟踪:GitHub Issues、Linear、Jira
- 通讯:Slack、飞书、钉钉
- 数据库:PostgreSQL、MySQL、MongoDB
- CI/CD:GitHub Actions、Jenkins、GitLab CI
没有连接器,循环只能在代码仓库里自嗨;有了它,循环才能开 PR、更新工单、给你发消息。
5. 子代理(Sub-agents):写代码的和验收的必须是两个人
这是质量的命门。让写代码的模型评判自己的代码,就像让学生给自己的考试打分,它一定手下留情。
所以最高效的循环设计原则是:一个代理负责实现,另一个代理负责验证。Claude Code 在 .claude/agents/ 里定义,Codex 在 .codex/agents/ 里用 TOML 定义。常见的分工是三层:一个探索、一个实现、一个审查。
代价是多烧点 token,但这个钱真不能省,后面实战部分给大家看具体配置。
6. 状态(State):循环的记忆保障
前面说了,模型会遗忘,但仓库不会。所有正经的循环都靠外部状态记住"干到哪了"。常见的存储方式:
- Markdown 文件:STATE.md、PROGRESS.md
- 任务队列:tasks.json
- Issue 系统:GitHub Issues、Linear
- 数据库:SQLite
一个实际的 STATE.md 大概长这样:
# Loop State
## 2026-06-11
### 已完成
- [x] 修复 #123:登录页 CSS 错位
### 进行中
- [ ] 修复 #124:API 返回 500
- 尝试1:改 auth 中间件,测试没过
- 尝试2:排查数据库连接,进行中
### 待处理
- [ ] auth 模块补单元测试
下次循环启动,先读这个文件,就知道上次干到哪了,连失败的尝试都不会重复踩。
闭环 vs 开环:先分清你要哪种
循环有两种基本类型,适用场景完全不同:
| 闭环 | 开环 | |
|---|---|---|
| 目标 | 固定、可验证("测试全绿") | 开放、探索式("找出性能瓶颈") |
| 停止条件 | 条件满足自动停 | 预算/迭代次数耗尽才停 |
| 成本 | 可预估 | 容易失控 |
| 适合谁 | 所有人,尤其新手 | 预算充足的老手 |
一个合格的闭环,五样东西缺一不可:
- 明确的目标:精确定义"完成"长什么样
- 充足的上下文:VISION.md、ARCHITECTURE.md、RULES.md 这类文件备齐
- 受限的动作:只给必要的工具,不多给一分权限
- 客观的反馈:测试、lint、类型检查,机器说了算
- 清晰的停止条件:可验证的成功标准,外加迭代上限兜底
我的建议是都从闭环开始。等你完全摸透了闭环,预算也扛得住了,再去碰开环。
实战:搭一个自动修复 CI 失败的循环
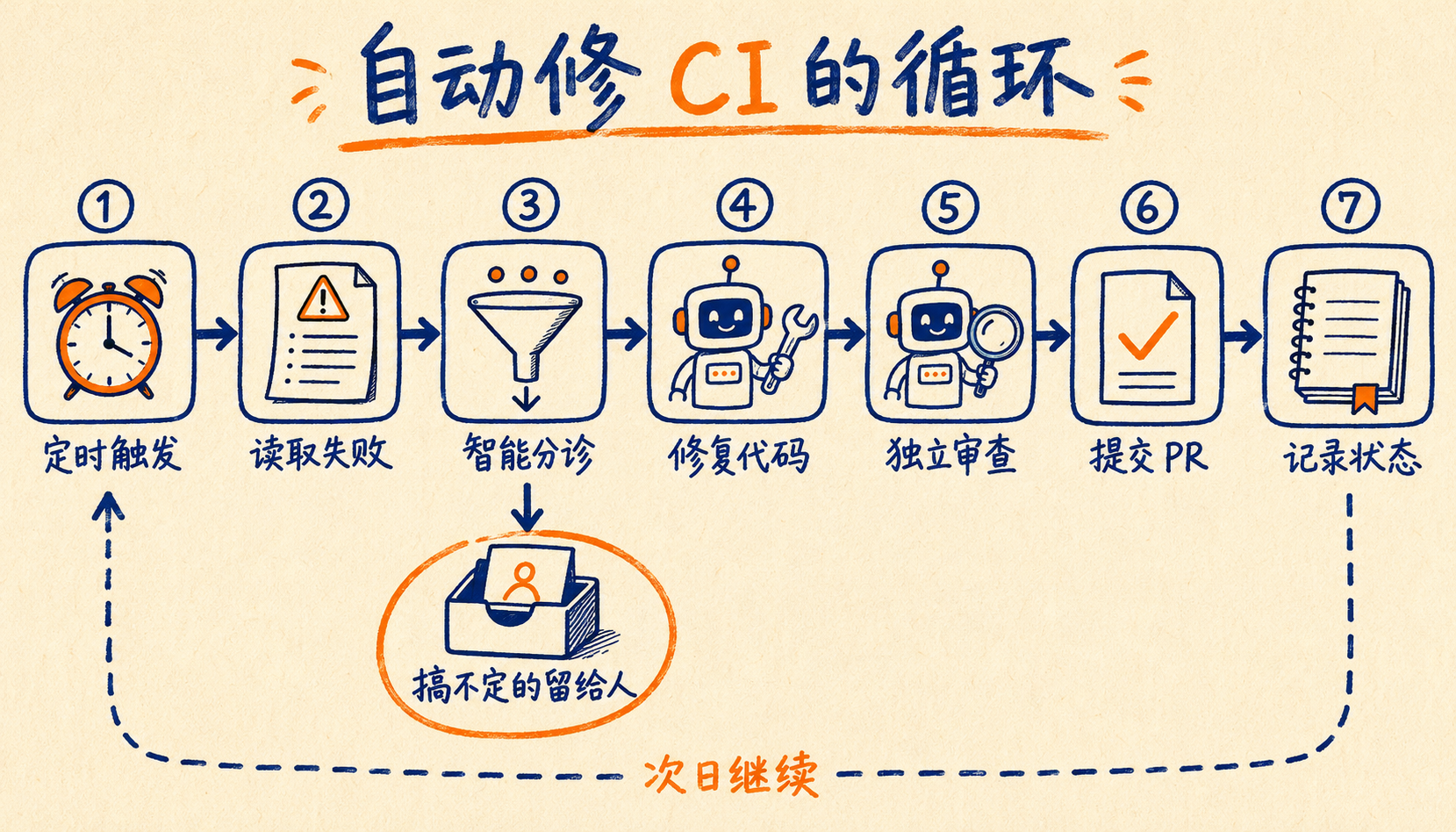
下面带大家完整走一遍,目标是:每天早上自动跑一次,把前一天 CI 挂掉的问题能修的修掉、开好 PR,搞不定的留给人。
整个循环跑起来是这样的:
步骤 1:准备项目结构
your-project/
.claude/
agents/
ci-fixer.md
code-reviewer.md
skills/
ci-triage/
SKILL.md
code-fixer/
SKILL.md
STATE.md
.github/
workflows/
ci-fix-loop.yml
步骤 2:写分诊技能
skills/ci-triage/SKILL.md:
# CI 分诊技能
## 目的
分析 CI 失败日志,定位根本原因,评估修复优先级。
## 输入
- CI 运行日志、失败的测试名和报错信息
## 分类规则
- 简单:语法错误、拼写错误、lint 警告
- 中等:报错信息明确的测试失败、依赖版本冲突
- 困难:间歇性失败、复杂逻辑错误、性能问题
## 输出格式
{
"issue_type": "test_failure",
"root_cause": "用户不存在时 user service 返回了 null",
"difficulty": "medium",
"auto_fixable": true,
"file_path": "src/services/user.js"
}
步骤 3:写修复技能
skills/code-fixer/SKILL.md:
# 代码修复技能
## 修复原则
1. 只修和 CI 失败直接相关的问题
2. 不顺手重构不相关的代码
3. 代码风格跟现有代码保持一致
4. 修完必须通过 lint 和类型检查
## 输出
- 修改后的文件、修复说明、测试运行结果
第 2 条特别重要。不写这条,AI 修一个 bug 能顺手给你"优化"二十个文件,review 的人直接崩溃。
步骤 4:配置子代理
干活的 .claude/agents/ci-fixer.md:
---
name: ci-fixer
description: 修复 CI 失败
tools: Edit, Bash, Read
---
用 code-fixer 技能修复指定的 CI 问题。
改完必须跑测试,测试通过才能开 PR。
验收的 .claude/agents/code-reviewer.md:
---
name: code-reviewer
description: 审查代码变更
tools: Read, Grep, Bash
---
审查代码变更的正确性、安全性和代码风格。
对照 skills 里的项目规范逐条检查,给出通过或退回的明确结论。
注意两点:干活的没有审查权,审查的没有改代码权;审查代理可以配更强的模型——干活用便宜的,把关用贵的,这是省钱和质量兼顾的常见搭配。
步骤 5:用 GitHub Actions 定时触发
.github/workflows/ci-fix-loop.yml(核心部分):
name: CI Fix Loop
on:
schedule:
- cron: '0 6 * * *' # 每天早上 6 点
workflow_dispatch: # 也允许手动触发
jobs:
fix-ci:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npm install -g @anthropic-ai/claude-code
- name: Run CI fix loop
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
claude -p "
用 ci-triage 技能分析昨天所有失败的 CI 运行。
对每个 auto_fixable 的问题:
1. 开独立分支
2. 派 ci-fixer 子代理修复
3. 派 code-reviewer 子代理审查
4. 审查通过才开 PR
5. 全部结果写入 STATE.md
搞不定的问题,在 STATE.md 里标记为待人工处理。
" --max-turns 50
- name: Commit state
run: |
git add STATE.md
git commit -m "update loop state" || true
git push
步骤 6:初始化状态文件
STATE.md:
# CI Fix Loop State
## 运行历史
### 2026-06-11
- 发现 3 个 CI 失败
- 自动修复 2 个,开了 PR #125、#126
- 1 个间歇性失败,标记待人工处理
## 待处理
- [ ] #127 间歇性测试失败,需要人看
这一步看着简单,但它就是整个循环的"记忆",千万别省。
到这就齐活了。第二天早上你打开 GitHub,看到的是几个已经过完独立审查的 PR 在等你拍板,外加一份"哪些事需要人处理"的清单。
成本与安全:丑话说在前面
循环很强,但用不好,账单和事故都会找上门。这部分是我自己实践下来最想提醒大家的。
先说钱。 循环烧 API 额度的速度远超手动模式,在一个中等规模代码库上跑 50-100 次迭代,花掉几百到上千块很正常。几条管控经验:
- 永远不要省略最大迭代数。没有 max-iterations 的循环就是一张空白支票
- 从 10-20 次迭代的小规模开始,观察几天行为再扩大
- 算 ROI:花 500 块的循环帮你省 20 小时,值;替你干一个 30 分钟的活,不值
- 便宜模型干粗活,贵模型把关:分诊、修复用 Sonnet 级别就够,审查再上强模型
- 设置每日用量警报,避免早上醒来看到惊喜账单
再说安全。 几条底线:
- 第一个循环从只读任务开始——只分析、只写报告,不改代码不合并,最坏的结果也就是一份没用的报告
- 工具权限用白名单,删库、改生产配置这类操作永远不进白名单
- 循环产出的代码,合并前必须有人看。验收代理给的"通过"是一个声明,不是证明
- 每一轮干了什么都留日志,出问题能查
最后还有一个比账单更隐蔽的坑:循环交付代码的速度,可能远超你理解代码的速度。哪天你发现仓库里大片代码自己既没写过也没真正读懂过,那就是该踩刹车的信号。Addy Osmani 原文里有句话我印象很深,送给大家:
像一个打算继续当工程师的人那样构建循环,而不是像一个只负责按启动键的人。
最后唠几句
三年时间,我们从"怎么问 AI"卷到"怎么让 AI 自己干",变化确实快。但循环工程的门槛其实不在技术——配置文件上面都给你了——而在于你愿不愿意把一件模糊的活儿想清楚:什么算完成?哪些动作允许?失败了怎么办?什么时候必须停?
这四个问题答得越清楚,你的循环就越靠谱。反过来说,连人都说不清的目标,AI 转一万圈也转不出来。
建议今天就动手:挑一件无聊但天天要干的事(CI 分诊就很合适),搭一个只读的闭环,跑一个礼拜看看。等你看到第一份循环自动生成的报告时,你就明白 Boris Cherny 那句"我的工作就是写循环"是什么感觉了。
我是老邓,咱们下篇见。