- 新增 GPT-5.4 深度解析文章,涵盖六大核心能力详解 - 添加 SVG 格式的 GPT-5.4 能力全景图 - 添加 Mermaid 格式的模型家族关系图 - 添加 GPT-5.4 六大能力思维导图 - 添加 Computer Use 工作流程图 - 添加 OSWorld 桌面操作基准测试图表 - 添加 上下文窗口演进对比图 - 添加 上下文压缩原理图 - 添加 Tool Search 机制对比图 - 添加 可配置推理深度图 - 添加 GDPval 对比图表 - 添加 三方模型对比图 - 添加 API 定价对比图 - 添加 Mermaid 配置文件和样式文件 - 添加模型选择指南 SVG 图片
14 KiB
GPT-5.4 深度解析:OpenAI 的全能战士来了
发布日期:2026-03-16 分类:技术解读 / 深度分析 作者:老邓唠AI

引子:这次不只是"更强",而是"会干活了"
3 月 5 日深夜,OpenAI 扔出了一颗重磅炸弹——GPT-5.4。
如果你以为这又是一次"跑分更高、回答更准"的常规升级,那你低估了这次更新的意义。GPT-5.4 不只是变聪明了,它第一次学会了操作电脑。
是的,你没看错。它能看到你的屏幕截图,然后像一个真人一样移动鼠标、点击按钮、敲键盘——帮你订机票、填表格、发邮件、操作 Excel。在桌面操作测试中,它的表现超越了人类。
这不是概念演示。这是已经上线的 API,任何开发者今天就能调用。
今天老邓带你全面拆解 GPT-5.4 的六大核心能力、跑分数据、定价策略,以及它跟 Claude Opus 4.6、Gemini 3.1 Pro 的正面对决。
一、GPT-5.4 是什么?
GPT-5.4 是 OpenAI 于 2026 年 3 月 5 日发布的最新旗舰模型,官方定义为**"最强大且高效的专业工作前沿模型"**。
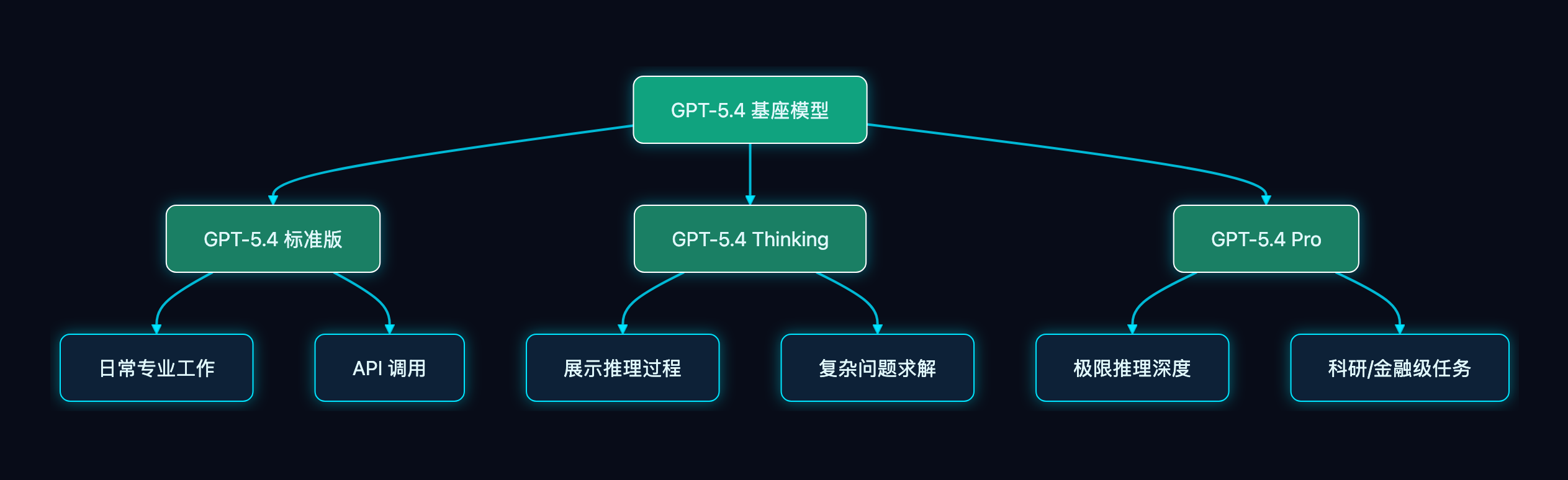
它不是一个模型,而是一个模型家族:
| 版本 | 定位 | 适用人群 |
|---|---|---|
| GPT-5.4 | 标准版,日常专业工作 | ChatGPT Plus / Team / API 开发者 |
| GPT-5.4 Thinking | 推理增强版,展示思考过程 | ChatGPT Plus / Team / Pro |
| GPT-5.4 Pro | 最高性能版,极限推理深度 | ChatGPT Pro / Enterprise / API |
三个版本共享同一个基座模型,区别在于推理深度和计算资源分配。

二、六大核心能力拆解
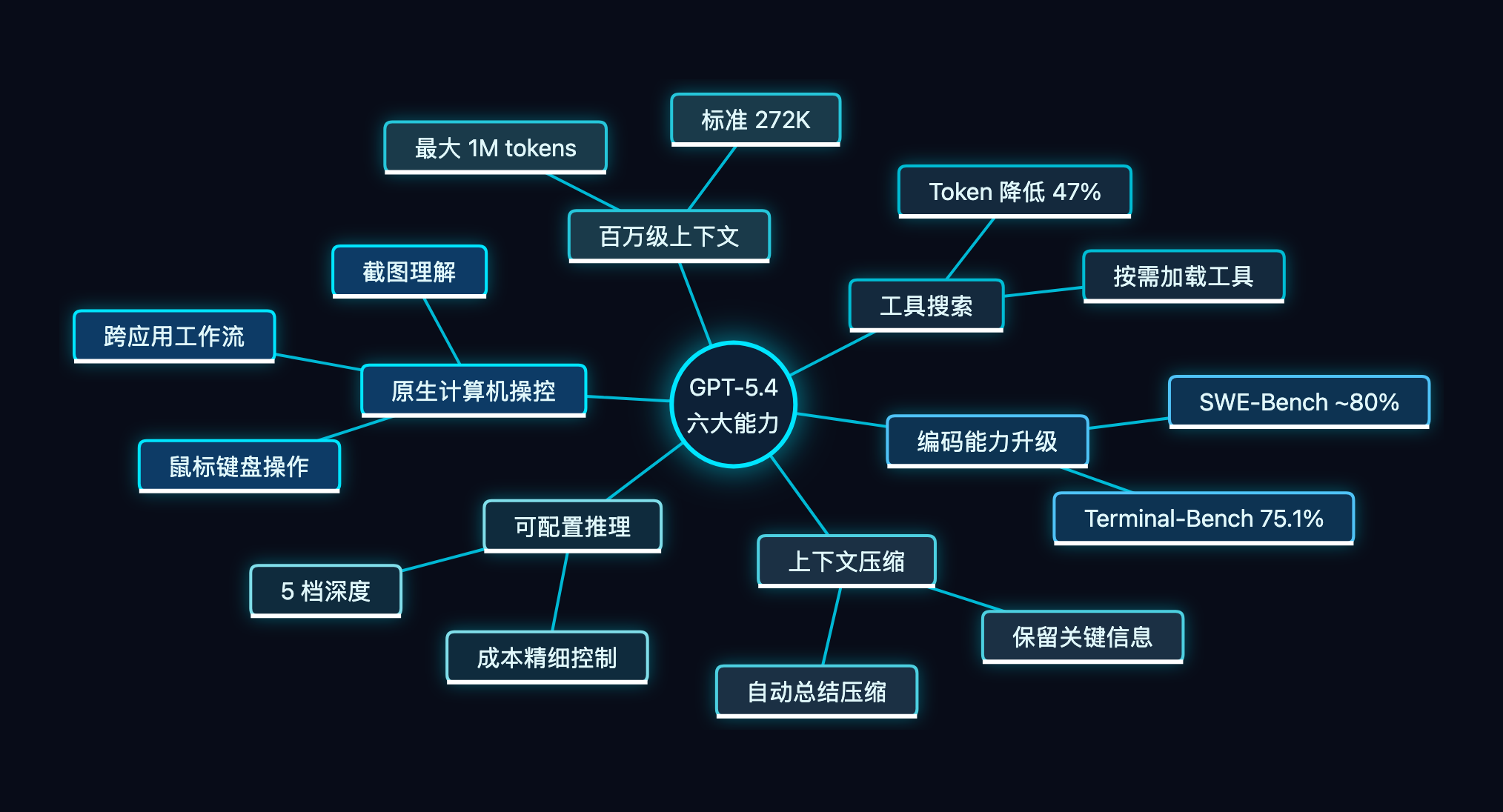
2.1 原生计算机操控(Computer Use)
这是 GPT-5.4 最炸裂的能力——OpenAI 首个原生支持计算机操控的通用模型。

它的工作方式很直觉:

- 看屏幕:模型接收桌面/浏览器的截图
- 理解界面:识别按钮、输入框、菜单等 UI 元素
- 发出指令:返回结构化的鼠标移动、点击、键盘输入动作
- 你的程序执行:由你的代码(harness)将这些动作应用到真实环境
简单说,GPT-5.4 就像一个坐在你电脑前的远程助手,看着屏幕告诉你"点这里、输入那个"。
实际能做什么?
- 自动填写复杂的 Web 表单
- 跨应用操作工作流(打开邮件 → 读取内容 → 创建日历事件)
- 操作 ERP、CRM 等企业系统
- 自动化测试 Web 应用
跑分有多强?
| 基准测试 | GPT-5.4 | GPT-5.2 | 人类表现 |
|---|---|---|---|
| OSWorld-Verified(桌面操作) | 75.0% | 47.3% | 72.4% |
| WebArena-Verified(浏览器操作) | 67.3% | - | - |
| Online-Mind2Web(截图识别) | 92.8% | - | - |
OSWorld 75.0%,人类 72.4%——AI 在桌面操作任务上,第一次超越了人类基准。
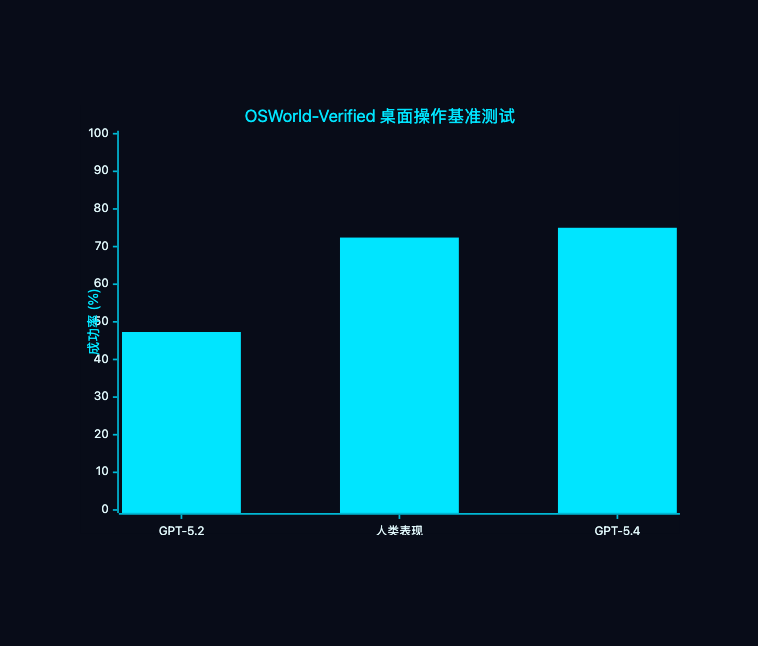
当然也有局限:截图传输有延迟,密集 UI 元素(如超大表格)的精确度还不够完美。但作为 v1 版本,这个起点已经足够惊艳。
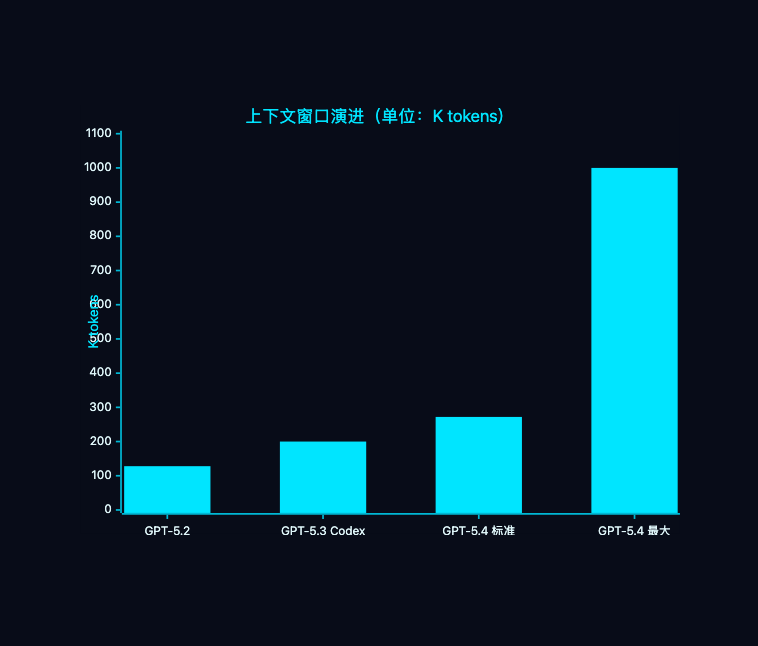
2.2 百万级上下文窗口
GPT-5.4 的标准上下文窗口为 272K tokens(比 GPT-5.3 Codex 的 200K 扩大了 36%),而通过 Codex 配置,可以解锁高达 100 万 tokens 的超大上下文。
100 万 tokens 是什么概念?
| 内容类型 | 大约容量 |
|---|---|
| 普通中文文字 | 约 150 万字 |
| 代码 | 约 75 万行 |
| PDF 文档 | 约 3000 页 |
这意味着你可以把一整个代码仓库、一本完整的技术手册、或者几个月的聊天记录一次性喂给模型,它都能理解和引用。
对于 Agent 场景尤其关键——智能体在执行长链条任务时,不会因为"忘了之前做过什么"而翻车。
2.3 上下文压缩(Compaction)
大上下文的问题是贵。100 万 tokens 每个请求都要收费,成本飞涨。
GPT-5.4 引入了一个巧妙的解决方案——Compaction(上下文压缩)。这是 OpenAI 首个在主线模型中训练支持的压缩能力。

它的原理是:在长对话或 Agent 执行过程中,模型会自动总结和压缩早期的上下文,保留关键信息,丢弃冗余细节。这样即使对话轮次很多,也不会撑爆上下文窗口。
开发者可以通过两个参数来控制:
model_context_window:设置最大上下文窗口model_auto_compact_token_limit:设置触发自动压缩的阈值
2.4 工具搜索(Tool Search)
这是一个面向 API 开发者的重磅特性。
传统做法是把所有工具的定义一股脑塞进 prompt,100 个工具的 schema 轻松吃掉几万 tokens。GPT-5.4 的工具搜索彻底改变了这个局面。
新方案:
- 模型只接收一个轻量的工具列表(名称 + 简短描述)
- 需要用某个工具时,按需加载该工具的完整定义
- 用完即弃,不占用后续请求的 token
效果?Token 使用量直降 47%,准确率不变。
对于构建大规模 Agent 系统的团队来说,这意味着成本直接砍半。

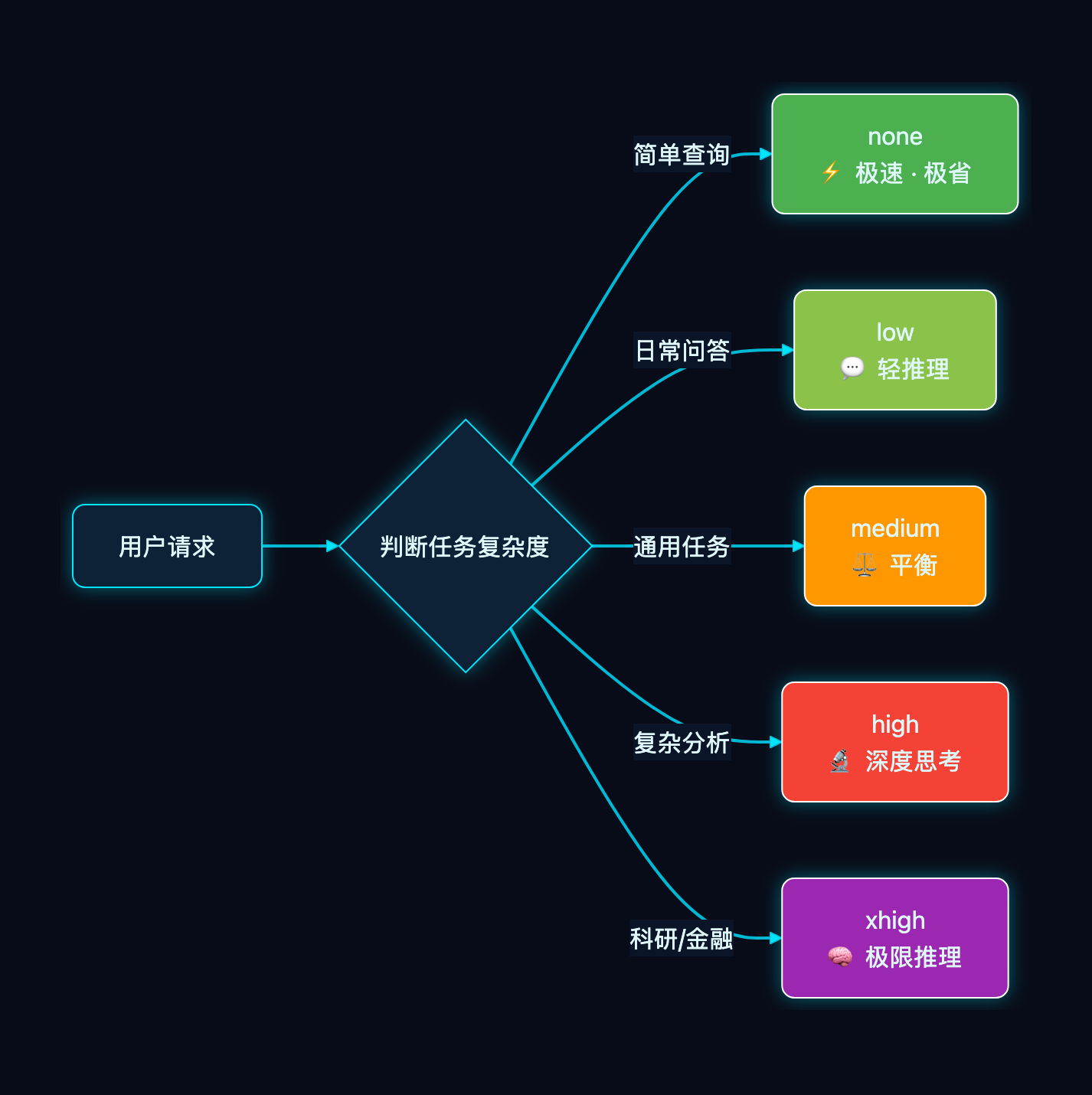
2.5 可配置推理深度
GPT-5.4 提供了 5 档推理深度,开发者可以精细控制模型的"思考力度":
| 档位 | 用途 | 成本 |
|---|---|---|
none |
直接回答,不推理 | 最低 |
low |
简单逻辑、摘要 | 低 |
medium |
通用场景,平衡性价比 | 中 |
high |
多步分析、自我修正 | 高 |
xhigh |
极限推理,科研级 | 最高 |
不同场景用不同档位,简单问题不浪费算力,复杂问题全力以赴——这是一个非常实用的成本优化手段。
2.6 编码能力大幅升级
GPT-5.4 融合了 GPT-5.3 Codex 的编码能力,在代码任务上表现惊人:
| 基准测试 | GPT-5.4 | GPT-5.3 Codex | Claude Opus 4.6 |
|---|---|---|---|
| SWE-Bench Verified | ~80.0% | 75.2% | 80.8% |
| HumanEval | 95.1% | 93.8% | 94.6% |
| Terminal-Bench 2.0 | 75.1% | - | 65.4% |
| SWE-Bench Pro | 57.7% | - | - |
在 SWE-Bench Verified(真实 GitHub issue 修复能力)上,GPT-5.4 与 Claude Opus 4.6 仅差 0.8 个百分点,几乎持平。而在 Terminal-Bench 2.0(终端操作能力)上,GPT-5.4 以 75.1% 的成绩大幅领先。
三、专业知识工作:逼近人类专家
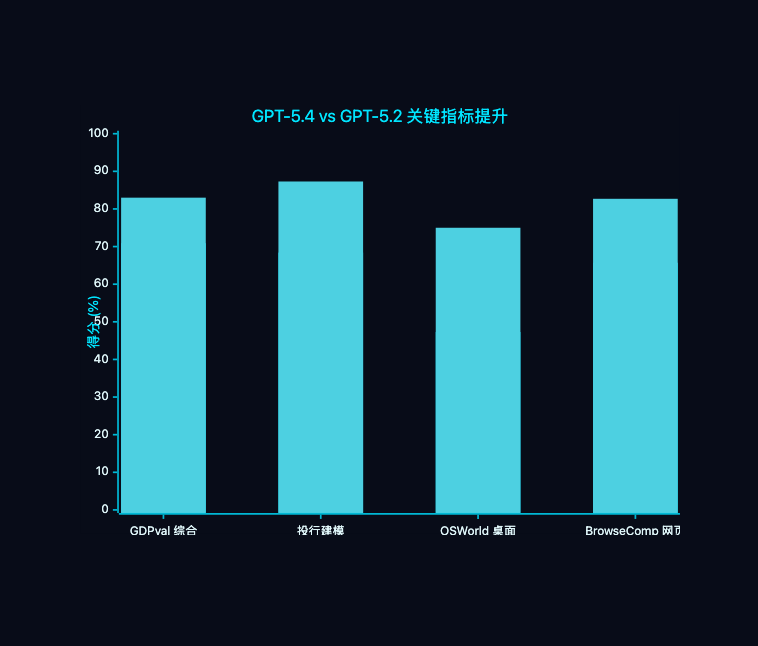
GPT-5.4 最让行业震动的数据来自 GDPval 基准测试——这个测试覆盖 44 个职业领域,衡量模型在"真实经济价值工作"中的表现。
| 指标 | GPT-5.4 | GPT-5.2 | 提升 |
|---|---|---|---|
| GDPval 综合 | 83.0% | 70.9% | +12.1% |
| 投行电子表格建模 | 87.3% | 68.4% | +18.9% |
| 演示文稿偏好率 | 68.0% | 32.0% | - |
| 错误率降低 | -33% | - | 单个陈述 |
| 整体回答错误率降低 | -18% | - | 完整回答 |
83% 的 GDPval 成绩意味着什么? 在 44 个职业领域中,GPT-5.4 的工作输出质量已经接近行业从业者的平均水平。投行建模 87.3%,比 GPT-5.2 猛涨近 19 个百分点——这不是微调,这是质的飞跃。
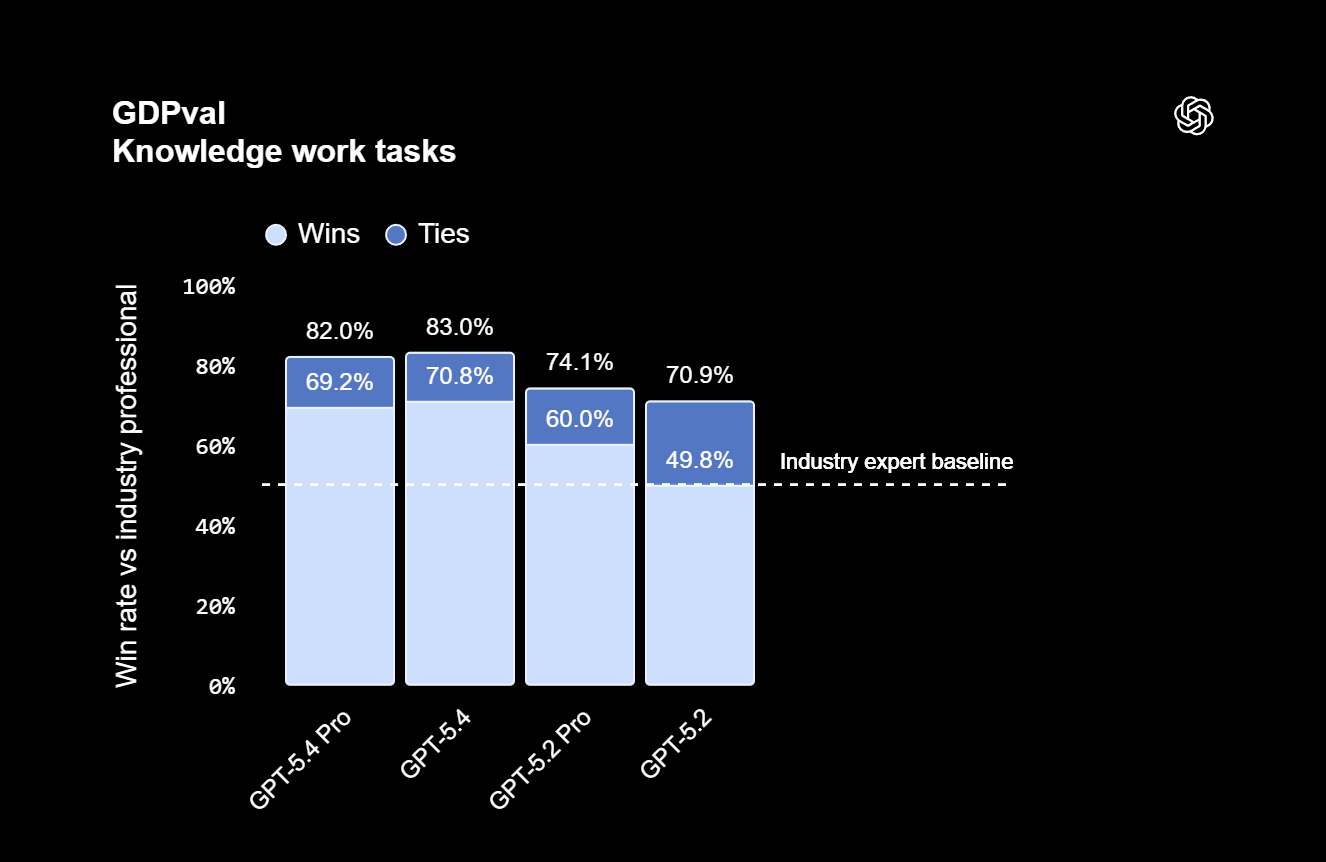
浅色 = GPT-5.2,深色 = GPT-5.4
四、三国争霸:GPT-5.4 vs Claude Opus 4.6 vs Gemini 3.1 Pro
2026 年 3 月,三大 AI 巨头的旗舰模型罕见地同台竞技。老邓帮你拉了一张全维度对比表:
4.1 基准跑分对比
| 基准测试 | GPT-5.4 | Claude Opus 4.6 | Gemini 3.1 Pro | 谁赢了 |
|---|---|---|---|---|
| GDPval(知识工作) | 83.0% | 78.0% | - | GPT-5.4 |
| GPQA Diamond(科学推理) | 92.8% | 91.3% | 94.3% | Gemini |
| ARC-AGI-2(抽象推理) | 73.3% | 75.2% | 77.1% | Gemini |
| MMMU Pro(视觉理解) | 81.2% | 85.1% | 80.5% | Claude |
| SWE-Bench Verified(代码修复) | ~80.0% | 80.8% | 80.6% | Claude(微弱) |
| Terminal-Bench 2.0(终端操作) | 75.1% | 65.4% | 68.5% | GPT-5.4 |
| OSWorld(桌面操控) | 75.0% | - | - | GPT-5.4 |
| BrowseComp(网页浏览) | 82.7% | 84.0% | 85.9% | Gemini |
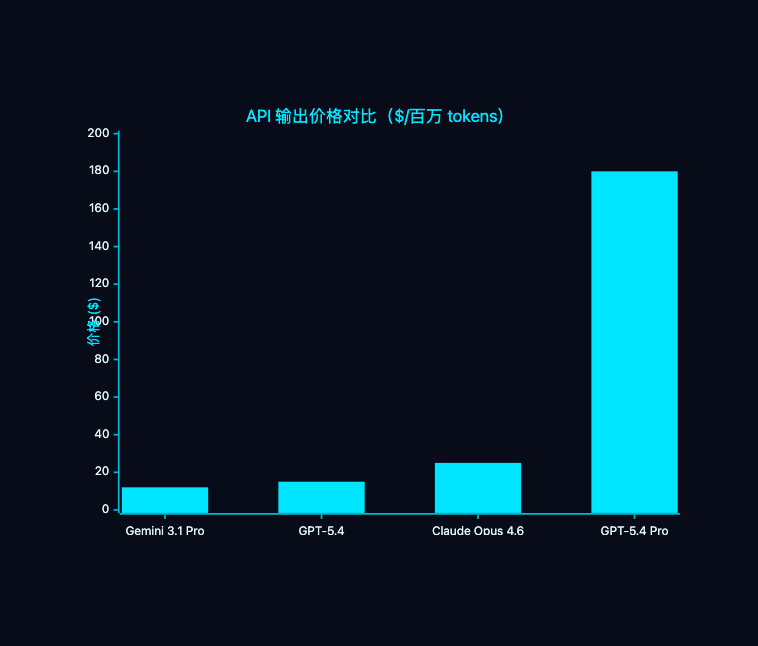
4.2 定价对比
| 模型 | 输入价格(/百万 tokens) | 输出价格(/百万 tokens) | 上下文窗口 |
|---|---|---|---|
| Gemini 3.1 Pro | $2 | $12 | 2M |
| GPT-5.4 | $2.50 | $15 | 272K(最大 1M) |
| Claude Opus 4.6 | $5 | $25 | 200K |
| GPT-5.4 Pro | $30 | $180 | 272K(最大 1M) |
4.3 各家优势领域一目了然

4.4 怎么选?
一句话总结:没有全能冠军,只有场景之王。
- 选 GPT-5.4:如果你需要桌面自动化、知识工作、工具编排——它是唯一一个 Computer Use 超越人类的模型
- 选 Claude Opus 4.6:如果你的核心场景是代码开发、多文件重构、视觉理解——它在 SWE-Bench 和 MMMU Pro 上仍然最强
- 选 Gemini 3.1 Pro:如果你预算有限但要求高质量推理——它用 GPT-5.4 Pro 十五分之一的价格,达到了同级别的科学推理水平
五、定价与可用性
5.1 API 定价
| 模型 | 输入 | 输出 | 备注 |
|---|---|---|---|
| GPT-5.4 | $2.50/M | $15/M | 标准档 |
| GPT-5.4 Pro | $30/M | $180/M | 极限性能 |
| Batch 模式 | 标准 50% | 标准 50% | 异步批量处理 |
| Flex 模式 | 标准 50% | 标准 50% | 弹性定价 |
| Priority 模式 | 标准 200% | 标准 200% | 优先响应 |
5.2 谁能用?
| 渠道 | 可用版本 |
|---|---|
| ChatGPT Plus / Team | GPT-5.4 Thinking |
| ChatGPT Pro / Enterprise | GPT-5.4 Thinking + GPT-5.4 Pro |
| API | gpt-5.4、gpt-5.4-pro |
GPT-5.2 Thinking 将保留至 2026 年 6 月 5 日,之后下线。如果你还在用旧版,记得提前迁移。

六、老邓的观点
说几句大实话。
GPT-5.4 最大的意义不在跑分,而在 Computer Use。
跑分上,GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro 三家在大多数评测中只差 2-3 个百分点,说实话对普通用户几乎没有体感差异。真正拉开差距的是能力维度的拓展。
Computer Use 让 AI 第一次真正能"用电脑"。这不是花活,这是生产力工具的范式转变。想象一下:
- 财务人员让 AI 自动操作 SAP 系统出报表
- 运营人员让 AI 自动在后台批量上架商品
- HR 让 AI 自动在多个招聘平台发布岗位
这些场景以前需要 RPA(机器人流程自动化)工具,写一堆脆弱的规则脚本。现在?给 GPT-5.4 一个截图,它自己看着干。
当然,v1 版本还有明显的局限——延迟、精确度、安全边界都需要打磨。但方向是对的,OpenAI 在这一局抢了先手。
另一个被低估的特性是 Tool Search。 47% 的 token 节省对大规模 Agent 系统来说是巨大的成本优化,这个设计思路值得所有做 AI 应用的团队学习。
最后说说价格。 Gemini 3.1 Pro 用十五分之一的价格打到了同级别的推理水平,Google 在性价比上确实卷得最狠。但 OpenAI 的 Batch 和 Flex 半价模式也很香,异步场景下成本可以压得很低。
总之,2026 年的 AI 模型市场,已经不是"谁最强"的问题了,而是**"谁在你的场景里最合适"**。
参考资料
- Introducing GPT-5.4 | OpenAI
- OpenAI launches GPT-5.4 with Pro and Thinking versions | TechCrunch
- GPT-5.4: Native Computer Use, 1M Context Window, Tool Search | DataCamp
- GPT-5.4 vs Opus 4.6 vs Gemini 3.1 Pro: Best AI Model? | DigitalApplied
- GPT-5.4 Release Date, Features & Pricing | NxCode
- OpenAI GPT-5.4 正式登场 | IT之家
- Computer Use API | OpenAI
- GPT-5.4 API Developer Guide | NxCode