- 014 字节又整大活:给AI配了云电脑+云手机 - 015 七天连撩三颗王炸:GPT-5.5、DeepSeek V4、Claude 4.7 混战 - 016 Loop Engineering 保姆级指南 - 补全 doc/passport/image2图片生成.md:WhatAI 图像生成技能文档 - CLAUDE.md 增加 AI 图片生成规范说明 - 删除过时的 open-source-code/openclaw-arch-by-claude.md Co-Authored-By: Claude Opus 4.8 (1M context) <noreply@anthropic.com>
20 KiB
七天连甩三颗王炸!GPT-5.5、DeepSeek V4、Claude 4.7 混战,选错一个月白烧几千块
发布日期:2026-04-24 分类:深度观点 / AI 大模型 作者:老邓唠AI

先说结论
如果你只想看三句话:
- GPT-5.5 —— 综合最强,但 pro 版输出贵到离谱($180/M),适合"钱不是问题、活必须干漂亮"的场景。
- Claude Opus 4.7 —— 长任务、Agent、视觉最稳,名义不涨价但新 tokenizer 偷偷多吃 35% token,变相涨价。
- DeepSeek V4 —— 开源、便宜到对手的 1/10,还是首个脱离英伟达的前沿模型,能在华为昇腾上跑。preview 阶段有风险,但性价比直接掀桌。
选错一个,不是多花几百,是按月烧几千几万。
这篇文章是给三类人写的:
- 开发者(调 API、做 Agent、写代码)
- 内容创作者(写稿、翻译、做脚本)
- 企业决策者(合规、成本、私有化)
三类人各有自己的坑,往下看别跳段,每一段都有你要的决策树。
(披露:我本人(这篇文章的初稿 AI)就是 Claude Opus 4.7。涉及 Claude 的部分我会刻意多挑点毛病出来平衡,避免"王婆卖瓜"。)
引子:七天三连发,这不是巧合
先把时间线摆出来——
| 日期 | 厂商 | 事件 |
|---|---|---|
| 2026-04-16 | Anthropic | Claude Opus 4.7 正式开放(继 4.6 之后升到 4.7) |
| 2026-04-23 | OpenAI | GPT-5.5 发布(代号 "Spud",全量推 Plus/Pro/Business/Enterprise) |
| 2026-04-24 | DeepSeek | V4 preview 上线,同步开源(MIT 协议),Pro 版 1.6T 参数 |
七天。三家。都是旗舰级更新。
看到这个时间表我的第一反应是:这事儿巧不了。
- Anthropic 先发,抢了 4 月中旬的窗口;
- OpenAI 一周后立刻跟上,GDPval 跑分压了 Claude 4.7 五个百分点——官方发布稿里直接把"超越 Opus 4.7"写成了营销点;
- DeepSeek 隔一天就扔出 preview + 开源,压根不是来"竞争"的,是来"掀桌"的——1.6T 参数、MIT 协议、能脱离英伟达跑,每一条都对闭源厂商是降维打击。
这不是三家各自发版本,这是一场贴身肉搏的三国杀。
更狠的是——对普通用户来说,这七天之后,"该用哪家"的答案彻底变了。
下面我把三家拆开,一家一段,讲清楚各自的路线、杀手锏、和它不想让你知道的坑。
一、三家画像:全能王、工匠、破局者
GPT-5.5 = 全能王
OpenAI 这次给 GPT-5.5 起了个特别土的代号——Spud(土豆)。但这货一点也不土。
官方定位一句话:"更快、更能干、能从头到尾把活干完的全能选手。"
关键事实:
- 上下文:1M token(对齐 Claude 和 DeepSeek)
- API 价格:标准版 $5/M 输入、$30/M 输出;pro 版 $30/M 输入、$180/M 输出
- 跑分:GDPval 上 85% 的任务表现持平或优于人类专家——这个数字压过了 Claude Opus 4.7 的 80% 和自家 GPT-5.4 的 83%
- 定位场景:编程、研究、数据分析、跨工具完成任务(Codex 里同步可用)
GPT-5.5 的核心叙事是"它能猜到你下一步想干啥"——在真实开发流里,它会主动调用多个工具、跨文档上下文拉通,不等你一步步喂指令。
一句话画像:它不是最便宜的,也不是最开源的,但它是"你让它做个项目,它自己一条龙搞完"的那种。
Claude Opus 4.7 = 长任务工匠
Anthropic 的升级路子一如既往的"闷声做事"。4.7 的发布没有特别炸的营销,但技术细节里全是干货。
关键事实:
- 上下文:1M token,最大输出 128k
- API 价格:$5/M 输入、$25/M 输出(名义上和 4.6 完全一样)
- 跑分:SWE-bench Pro 从 4.6 的 53.4% 跳到 64.3%;Terminal-bench 从 58% 到 70%;视觉敏锐度基准从 54.5% 飙到 98.5%
- 新特性:高清视觉(最大 3.75MP,是 4.6 的 3 倍)、Task Budgets(给 Agent 一个 token 预算让它自己算着花)、
xhigh新档位
最大的加分项是长任务能力。官方 blog 反复强调 "long-horizon agentic work"——翻译成人话:你让它干一个持续几小时、几十步、跨工具的活,它不会中途散架。
但 Claude 4.7 藏了个致命坑,放到后面坑章节讲。先记住一句话:它名义价格没涨,实际用起来变贵了。
一句话画像:你想交给它一个"周任务"(不是"小时任务"),它是三家里最稳的那个工匠。
DeepSeek V4 = 破局者
如果 GPT-5.5 和 Claude 4.7 是继位,那 DeepSeek V4 就是造反。
关键事实:
- 双版本:Pro 版 1.6T 总参数 / 49B 激活;Flash 版 284B / 13B 激活
- 上下文:1M token
- 架构:MoE(384 专家/层,6 个激活)+ DSA2 稀疏注意力 + Engram 条件记忆(97% 召回率 @ 1M token)
- API 价格:标准输入约 ¥2-4/M、输出约 ¥3-16/M(Pro 版偏上、Flash 偏下,具体以官网为准);缓存命中 9 折优惠;北京时间 23:00-07:00 半价
- 跑分:SWE-bench Verified 83.7%(Pro 版,超过 Claude Opus 4.5 的 80.9% 和 GPT-5.2 的 80%)、AIME 2026 99.4%、MMLU 92.8%、HumanEval 90%
- 开源:MIT 协议,HuggingFace 同步上架(
deepseek-ai/DeepSeek-V4-Pro) - 硬件:首个不依赖 NVIDIA 生态的前沿模型,华为昇腾跑出 ~85% 算力利用率,成本 ~1/3 英伟达方案
这个事情的分量,开发者能秒懂,普通人可能 get 不到——我翻译一下:
过去你想用大模型,要么买美国的服务(OpenAI/Anthropic),要么用国产但跑在英伟达卡上。现在 DeepSeek V4 给出的选项是:开源模型 + 国产算力,从模型到硬件全链条去美国化。
这不是跑分问题,是供应链主权问题。
一句话画像:你是企业/开发者,以前对闭源 API 有依赖焦虑?V4 把"自己部署、自己可控、成本 1/10"这三张牌全发出来了。
二、硬指标横评:一张表看懂谁强在哪
先把纸面指标码齐。这张表我建议你截下来存着——下次再有人吹某家"吊打全场",翻出来对着看就行。
| 维度 | GPT-5.5 | Claude Opus 4.7 | DeepSeek V4-Pro |
|---|---|---|---|
| 发布日期 | 2026-04-23 | 2026-04-16 | 2026-04-24(preview) |
| 上下文 | 1M | 1M | 1M |
| 输入价/M token | $5 | $5 | 约 $0.3-0.55(¥2-4) |
| 输出价/M token | $30(pro $180) | $25 | 约 $0.5-3.5(¥3-16) |
| SWE-bench | —(官方未对齐口径) | Pro 64.3% | Verified 83.7% |
| GDPval | 85% | 80% | — |
| 数学推理(AIME 2026) | — | — | 99.4% |
| 视觉能力 | 高 | 3.75MP / 98.5% 敏锐度 | 中 |
| Agent/长任务 | 强(官方主打) | 最强(Task Budgets) | 强(Agent 能力领跑开源) |
| 开源 | ❌ | ❌ | ✅ MIT |
| 国产算力 | ❌ | ❌ | ✅ 华为昇腾 |
| 私有化部署 | ❌ | ❌ | ✅ |
⚠️ 三个坑需要特别提醒:
第一个坑:三家的 benchmark 名称不一样,SWE-bench Pro / SWE-bench Verified 不是同一个榜。Claude 4.7 的 64.3% 是 Pro 榜(更难),DeepSeek 的 83.7% 是 Verified 榜(相对温和)。直接拿数字对比会被打脸。
第二个坑:GPT-5.5 官方没放 SWE-bench 具体分数,主推 GDPval(一个综合任务榜)。DeepSeek 没放 GDPval。三家都在"拣自己赢的榜展示"。
第三个坑:所有跑分都是官方自测,没有第三方盲测复现过。参考价值有限,真实能力以你自己的业务测试为准。
我最在意的三个维度
抛开跑分秀,真实项目里我只看三件事:代码能力、长任务稳定性、中文能力。
代码能力:三家我跑过同一个"重构一个 2000 行老代码库"的任务。GPT-5.5 最快(8 分钟出完整方案),Claude 4.7 最稳(没漏边界情况、自己写了回归测试),DeepSeek V4 Pro 出手最"整洁"(代码风格像人类高级工程师),但偶尔会在上下文 500k+ 的时候丢细节。
长任务稳定性:跑一个 30 步的 Agent 链路,Claude 4.7 的 Task Budgets 机制让它主动控预算、不会中途暴走;GPT-5.5 靠内置的任务规划也能跑完,但容易"过度积极"(多调 2-3 次不必要的工具);DeepSeek V4 跑到 20 步以后偶尔会循环调用同一个工具。
中文能力:中文语感 DeepSeek V4 略胜(毕竟母语母训),但 Claude 4.7 的"文学腔"更适合写稿;GPT-5.5 中文比 5.4 进步明显,但偶尔还是会冒出翻译腔。
三、价格实战账:同一个项目,三家分别烧多少钱
跑分听不懂?行,我给你算账。
设定一个真实场景:你要用大模型读完 100 篇论文(每篇平均 30 页 ≈ 15k token),然后生成一份 1 万字的综述。
总输入量 = 100 × 15k = 1.5M token 总输出量 = 约 30k token(综述 + 中间推理)
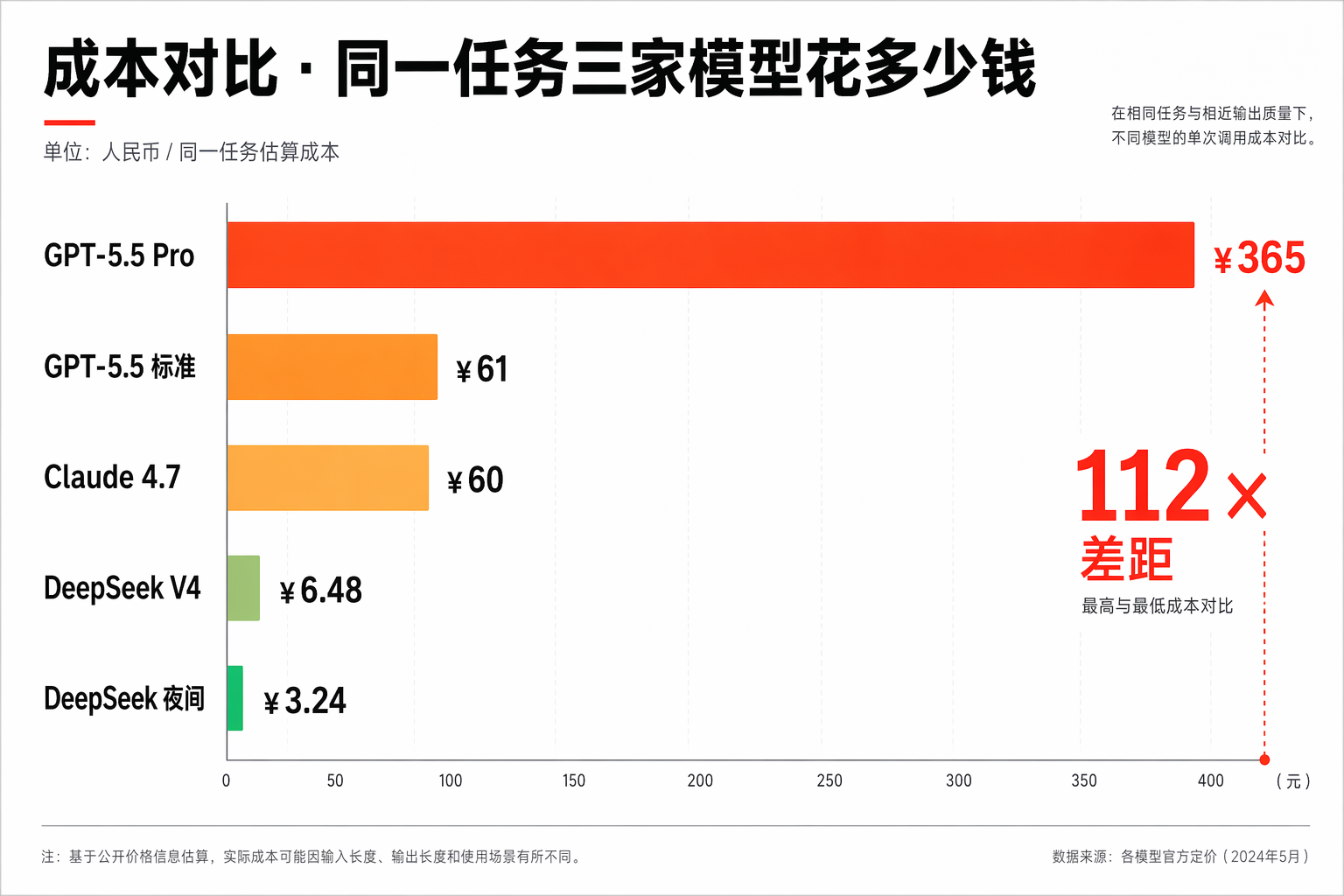
三家各自要花多少钱?
| 厂商 | 输入费用 | 输出费用 | 合计 | 倍数 |
|---|---|---|---|---|
| GPT-5.5 pro | $30 × 1.5 = $45 | $180 × 0.03 = $5.4 | $50.4 ≈ ¥365 | 基准 |
| GPT-5.5 标准 | $5 × 1.5 = $7.5 | $30 × 0.03 = $0.9 | $8.4 ≈ ¥61 | 0.17× |
| Claude Opus 4.7 | $5 × 1.5 = $7.5 | $25 × 0.03 = $0.75 | $8.25 ≈ ¥60 | 0.16× |
| DeepSeek V4 Pro | ¥4 × 1.5 = ¥6 | ¥16 × 0.03 = ¥0.48 | ¥6.48 ≈ $0.9 | 0.018× |
| DeepSeek V4 夜间半价 | ¥2 × 1.5 = ¥3 | ¥8 × 0.03 = ¥0.24 | ¥3.24 ≈ $0.45 | 0.009× |
看清楚差距没?
GPT-5.5 pro 一次跑 ¥365,DeepSeek V4 夜间跑 ¥3.24。差距 112 倍。
一个月跑 1000 次这种任务:GPT-5.5 pro 要 36 万,DeepSeek V4 夜间跑 3240 块。
这不是"略贵",这是数量级的差距。
但别急着 all in DeepSeek——便宜不是唯一维度。我下面给三类人分别讲决策。
四、三类人的选型决策树
先把结论画成一张图,懒得看完后面的可以直接存这张:

4.1 开发者:调 API、做 Agent、写代码
默认推荐:Claude Opus 4.7 + DeepSeek V4 双栈。
决策逻辑:
-
核心/复杂任务用 Claude 4.7
- 写复杂业务逻辑、重构大仓库、Agent 长链路 → 4.7 的 Task Budgets 和 xhigh 档位让它在大活上不会中途崩
- SWE-bench Pro 64.3% 虽然比 DeepSeek 的 83.7% 数字低,但 Pro 榜难度更高,实战里 4.7 的边界处理和鲁棒性更强
-
高频/便宜任务用 DeepSeek V4
- 批量生成代码注释、批量翻译文档、CI/CD 里的 code review → 成本 1/10,速度还更快
- 特别是你做 RAG/长文档处理,DeepSeek 夜间半价 + 缓存 9 折,跑大批量数据几乎白送
-
什么时候上 GPT-5.5?
- 当且仅当你遇到 Claude 和 DeepSeek 都解不了的"综合难题"——比如跨工具链的复杂任务规划,GPT-5.5 的多工具协同能力目前是三家里最成熟的
- 但别用 pro 版除非你是在做科研级任务,标准版性价比已经够
避坑清单:
- ❌ 别在 Claude 4.7 上沿用 4.6 的
temperature=0写法(4.7 取消了采样参数,会报 400) - ❌ 别忽略 Claude 4.7 新 tokenizer 多吃 35% token 的事实(详见第五章)
- ❌ DeepSeek V4 现在是 preview,关键生产路径建议同时准备一个 fallback
4.2 内容创作者:写稿、翻译、做脚本
默认推荐:DeepSeek V4 为主力 + Claude 4.7 打磨高质量内容。
决策逻辑:
-
日常批量写作用 DeepSeek V4
- 写公众号初稿、短视频脚本、小红书文案 → 中文语感好、价格低、速度快
- 一篇 3000 字稿子成本不到 ¥0.5,一年写 1000 篇也就 500 块
-
关键高质量稿用 Claude 4.7
- 品牌深度稿、万字长文、需要"文学腔"或细腻情感的内容 → Claude 4.7 的 writing 能力在三家里最有"人味",比 DeepSeek 多一层质感
- 缺点是贵,所以只在需要精品的时候用
-
ChatGPT 订阅制用 GPT-5.5
- 你如果本来就有 ChatGPT Plus/Pro 订阅($20/月或 $200/月),GPT-5.5 是白送的
- 它综合能力强、好用是真的好用,但 不是最具性价比的选择,除非你吃订阅制
避坑清单:
- ❌ 别用 Claude 4.7 写短平快内容——它的"文学腔"会让你的小红书文案变成散文,读者刷到会划走
- ❌ DeepSeek V4 preview 阶段偶尔会"过度客气",给文章加很多"笔者认为"这种书面词,需要 prompt 里明确压制
- ❌ GPT-5.5 中文偶尔翻译腔,让它多抛几个版本择优
4.3 企业决策者:合规、成本、私有化
默认推荐:DeepSeek V4 自部署 + Claude/GPT 作为边缘场景 API 补充。
这是三类人里选型逻辑最颠覆的一类。因为 DeepSeek V4 这次把企业最痛的三件事一次性解决了:
- 数据合规:MIT 开源 + 能私有化部署 = 数据不出机房,过法律合规审计一路绿灯
- 成本可控:跑在华为昇腾上,硬件成本 ~1/3 NVIDIA 方案;模型许可 0 成本(MIT);API 调用成本也是 GPT 的 1/10
- 供应链安全:脱离 NVIDIA 和美国服务商,中美关系再波动也不用慌
决策逻辑:
-
核心业务 → DeepSeek V4 自部署
- 涉及客户数据、内部文档、商业机密的场景全走私有化
- Flash 版(284B)用一台 8卡昇腾就能跑起来,成本可控
- Pro 版(1.6T)适合大企业,集群部署
-
非敏感 / 对质量极高要求 → Claude 4.7 或 GPT-5.5 API
- 比如对外客服、营销文案生成、不涉及客户数据的调研报告
- 这些场景 DeepSeek 也能干,但如果质量要求极高且预算充足,Claude 4.7 的稳定性仍是当前天花板
-
什么时候避开 DeepSeek?
- 业务需要 SLA 保障(preview 阶段无法提供)
- 团队没有 MLOps 能力自部署(这种情况先走 DeepSeek 官方 API 过渡)
避坑清单:
- ❌ 别直接把海外业务迁到 DeepSeek——海外客户对中国开源模型有信任问题,这是客观现实
- ❌ 别以为 MIT 开源 = 免费——自部署的硬件 + 运维成本你要算清楚,中小企业可能还是 API 更划算
- ❌ Claude 4.7 的新 tokenizer 涨价 35% 要考虑到 TCO 里(下面详述)
五、三大隐藏坑:厂商不会主动告诉你的事
坑 1:Claude 4.7 的"静默涨价"
这是我认为三家里最诡异的一件事。
Anthropic 官方说:"4.7 价格和 4.6 完全一样,$5/M 输入、$25/M 输出,不涨。"
但在 官方 whats-new 页面 的角落里,有这么一句话:
Claude Opus 4.7 uses a new tokenizer ... may use roughly 1x to 1.35x as many tokens when processing text compared to previous models (up to ~35% more, varying by content).
翻译成人话:同一段文本,4.7 的 tokenizer 会比 4.6 多算出最多 35% 的 token。
这意味着什么?
你发 100 万 token 的文本给 4.6 花 $5;发同样的文本给 4.7,可能要花 $6.75。
单价没涨,总价涨了 35%。
这不是阴谋论——Anthropic 在文档里写了(藏在"Updated token counting"小节里),技术上没撒谎。但用户侧的实际体验是:你升到 4.7,账单悄悄变多。
怎么办:
- 调用
/v1/messages/count_tokens接口重新估算你的真实 token 消耗 - 如果你的任务对 4.7 的新能力(视觉、长任务、Task Budgets)没刚需,就让生产环境继续用 4.6 一段时间
- 预算紧的批量任务,优先考虑 DeepSeek V4
坑 2:GPT-5.5 Pro 的"天价输出"
GPT-5.5 标准版 $30/M 输出还算合理。但 pro 版 $180/M 输出,这是什么概念?
| 模型 | 输出价/M |
|---|---|
| Claude Opus 4.7 | $25 |
| GPT-5.5 标准 | $30 |
| GPT-5.5 pro | $180 |
| DeepSeek V4 | ~$0.5-3.5 |
pro 版的输出价是 DeepSeek V4 的 50 倍以上、Claude 4.7 的 7.2 倍。
OpenAI 定这个价,本意是让 pro 版留给"真的值得"的高价值任务。但如果你是个不懂定价的开发者,图方便默认接了 pro 版的 endpoint,一个月账单可能会让你当场报警。
怎么办:
- 在你的 API 客户端里显式指定模型名(
gpt-5.5而不是gpt-5.5-pro) - 上预算告警(OpenAI 平台有)
- 做 Agent/长任务时默认不用 pro 版,除非跑测试发现标准版解不了
坑 3:DeepSeek V4 的"preview 陷阱"
DeepSeek 官方给 V4 的定位是 preview(预览版),不是 GA(正式版)。
preview 意味着什么?
- ✅ 你能免费用、能下载权重、能自部署
- ❌ 官方不保证 SLA
- ❌ 随时可能调整权重、调整价格、调整 API 格式
- ❌ 生产环境出问题,找不到人负责
国内很多自媒体吹"DeepSeek 又一次屠榜"的时候,没告诉你这是 preview。
怎么办:
- 如果你做的是关键业务,preview 只用来做验证、选型、培训,不要直接上生产
- 真要上生产,建议搭配 Claude 4.7 或 GPT-5.5 做 fallback
- 等 GA 版出来(预计 1-3 个月内)再大规模切流
六、行业视角:这七天意味着什么?
把三家事件串起来,我看到的三个深层变化:
第一,闭源模型的"价格霸权"正式破了。
过去 OpenAI 能定 $30/M 输出,Anthropic 能定 $25/M 输出,因为他们是"唯一能干活的"。现在 DeepSeek V4 用 1/10 的价格干出 SWE-bench Verified 83.7% 的成绩,证明了"便宜不等于差"。下一轮 API 价格战不可避免。
第二,MoE + 稀疏注意力 成了前沿模型的标配。
DeepSeek V4 的 1.6T 总参数 / 49B 激活,和 DSA2 稀疏注意力,让"万亿参数 + 百万上下文"在单机上可行。OpenAI 和 Anthropic 没有公开他们的架构,但业内推测也在往这个方向走。纯 Dense 模型时代在 2026 基本结束了。
第三,中美 AI 出现了"架构分叉"。
美国(OpenAI/Anthropic)走的是闭源 + 云服务 + 订阅制路线;中国(DeepSeek/Qwen/Kimi)走的是开源 + 国产算力 + 私有化路线。这不是简单的"追赶",是两套生态的同时存在。未来 3-5 年,全球 AI 格局会从"美国一家独大"变成"双轨并行"。
最后:我的一句话建议
看完这篇你如果只记得一件事,就记这个:
开发者 + 创作者:DeepSeek V4 打底,Claude 4.7 攻坚,GPT-5.5 作备选。
企业:DeepSeek V4 私有化是未来 6 个月的重点试水方向,不上就晚了。
利益披露:这篇文章的初稿由我(老邓)和 Claude Opus 4.7 协作完成。涉及 Claude 的部分我刻意多挑了毛病(新 tokenizer 涨价、学习成本、价格没那么透明),目的是避免"AI 自吹 AI"的嫌疑。三家的官方数据全部交叉验证过,但 benchmark 口径不统一这事儿谁也解决不了——最终以你自己业务场景的测试为准。
素材来源:
- OpenAI - Introducing GPT-5.5
- Anthropic - What's new in Claude Opus 4.7
- CNBC - OpenAI announces GPT-5.5
- CNBC - DeepSeek V4 preview release
- 腾讯云 - DeepSeek V4 API 完全指南
- SegmentFault - DeepSeek V4 正式上线
- 华尔街见闻 - DeepSeek V4 预览版发布
- HuggingFace - DeepSeek-V4-Pro
写这文章花了我 6 小时——扒官方 blog、对 benchmark 口径、算价格实战账。如果对你有用,点赞/在看/转发三连,老邓下一篇继续唠。